Commit Procedures
For general guidance on contributing to VTR see Submitting Code to VTR.
The actual mechanics of submitting code are outlined below.
However they differ slightly depending on whether you are:
an internal developer (i.e. you have commit access to the main VTR repository at
github.com/verilog-to-routing/vtr-verilog-to-routing) or,an (external developer) (i.e. no commit access).
The overall approach is similar, but we call out the differences below.
Setup a local repository on your development machine.
a. External Developers
Create a ‘fork’ of the VTR repository.
Usually this is done on GitHub, giving you a copy of the VTR repository (i.e.
github.com/<username>/vtr-verilog-to-routing, where<username>is your GitHub username) to which you have commit rights. See About forks in the GitHub documentation.Clone your ‘fork’ onto your local machine.
For example,
git clone git@github.com:<username>/vtr-verilog-to-routing.git, where<username>is your GitHub username.
b. Internal Developers
Clone the main VTR repository onto your local machine.
For example,
git clone git@github.com:verilog-to-routing/vtr-verilog-to-routing.git.
Move into the cloned repository.
For example,
cd vtr-verilog-to-routing.Create a branch, based off of
masterto work on.For example,
git checkout -b my_awesome_branch master, wheremy_awesome_branchis some helpful (and descriptive) name you give you’re branch. Please try to pick descriptive branch names!Make your changes to the VTR code base.
Test your changes to ensure they work as intended and have not broken other features.
At the bare minimum it is recommended to run:
make #Rebuild the code ./run_reg_test.py vtr_reg_basic vtr_reg_strong #Run tests
See Running Tests for more details.
Also note that additional code formatting checks, and tests will be run when you open a Pull Request.
Commit your changes (i.e.
git addfollowed bygit commit).Please try to use good commit messages!
See Commit Messages and Structure for details.
Push the changes to GitHub.
For example,
git push origin my_awesome_branch.a. External Developers
Your code changes will now exist in your branch (e.g.
my_awesome_branch) within your fork (e.g.github.com/<username>/vtr-verilog-to-routing/tree/my_awesome_branch, where<username>is your GitHub username)b. Internal Developers
Your code changes will now exist in your branch (e.g.
my_awesome_branch) within the main VTR repository (i.e.github.com/verilog-to-routing/vtr-verilog-to-routing/tree/my_awesome_branch)Create a Pull Request (PR) to request your changes be merged into VTR.
Navigate to your branch on GitHub
a. External Developers
Navigate to your branch within your fork on GitHub (e.g.
https://github.com/<username/vtr-verilog-to-routing/tree/my_awesome_branch, where<username>is your GitHub username, andmy_awesome_branchis your branch name).b. Internal Developers
Navigate to your branch on GitHub (e.g.
https://github.com/verilog-to-routing/vtr-verilog-to-routing/tree/my_awesome_branch, wheremy_awesome_branchis your branch name).Select the
New pull requestbutton.a. External Developers
If prompted, select
verilog-to-routing/vtr-verilog-to-routingas the base repository.
Commit Messages and Structure
Commit Messages
Commit messages are an important part of understanding the code base and its history. It is therefore extremely important to provide the following information in the commit message:
What is being changed?
Why is this change occurring?
The diff of changes included with the commit provides the details of what is actually changed, so only a high-level description of what is being done is needed. However a code diff provides no insight into why the change is being made, so this extremely helpful context can only be encoded in the commit message.
The preferred convention in VTR is to structure commit messages as follows:
Header line: explain the commit in one line (use the imperative)
More detailed explanatory text. Explain the problem that this commit
is solving. Focus on why you are making this change as opposed to how
(the code explains that). Are there side effects or other unintuitive
consequences of this change? Here's the place to explain them.
If necessary. Wrap lines at some reasonable point (e.g. 74 characters,
or so) In some contexts, the header line is treated as the subject
of the commit and the rest of the text as the body. The blank line
separating the summary from the body is critical (unless you omit
the body entirely); various tools like `log`, `shortlog` and `rebase`
can get confused if you run the two together.
Further paragraphs come after blank lines.
- Bullet points are okay, too
- Typically a hyphen or asterisk is used for the bullet, preceded
by a single space, with blank lines in between, but conventions
vary here
You can also put issue tracker references at the bottom like this:
Fixes: #123
See also: #456, #789
(based off of here, and here).
Commit messages do not always need to be long, so use your judgement. More complex or involved changes with wider ranging implications likely deserve longer commit messages than fixing a simple typo.
It is often helpful to phrase the first line of a commit as an imperative/command written as if to tell the repository what to do (e.g. Update netlist data structure comments, Add tests for feature XYZ, Fix bug which ...).
To provide quick context, some VTR developers also tag the first line with the main part of the code base effected, some common ones include:
vpr:for the VPR place and route tool (vpr/)flow:VTR flow architectures, scripts, tests, … (vtr_flow/)archfpga:for FPGA architecture library (libs/libarchfpga)vtrutil:for common VTR utilities (libs/libvtrutil)doc:Documentation (doc/,*.md, …)infra:Infrastructure (CI,.github/, …)
Commit Structure
Generally, you should strive to keep commits atomic (i.e. they do one logical change to the code). This often means keeping commits small and focused in what they change. Of course, a large number of minuscule commits is also unhelpful (overwhelming and difficult to see the structure), and sometimes things can only be done in large changes – so use your judgement. A reasonable rule of thumb is to try and ensure VTR will still compile after each commit.
For those familiar with history re-writing features in git (e.g. rebase) you can sometimes use these to clean-up your commit history after the fact.
However these should only be done on private branches, and never directly on master.
Code Formatting
Some parts of the VTR code base (e.g. VPR, libarchfpga, libvtrutil) have C/C++ code formatting requirements which are checked automatically by regression tests. If your code changes are not compliant with the formatting, you can run:
make format
from the root of the VTR source tree.
This will automatically reformat your code to be compliant with formatting requirements (this requires the clang-format tool to be available on your system).
Python code must also be compliant with the formatting. To format Python code, you can run:
make format-py
from the root of the VTR source tree (this requires the black tool to be available on your system).
Large Scale Reformatting
For large scale reformatting (should only be performed by VTR maintainers) the script dev/autoformat.py can be used to reformat the C/C++ code and commit it as ‘VTR Robot’, which keeps the revision history clearer and records metadata about reformatting commits (which allows git hyper-blame to skip such commits). The --python option can be used for large scale formatting of Python code.
Python Linting
Python files are automatically checked using pylint to ensure they follow established Python conventions. You can run pylint on the entire repository by running ./dev/pylint_check.py. Certain files which were created before we adopted Python lint checking are grandfathered and are not checked. To check all files, provide the --check_grandfathered argument. You can also manually check individual files using ./dev/pylint_check.py <path_to_file1> <path_to_file2> ....
Sanitizing Includes
You can use include-what-you-use or the clangd language server to make sure includes are correct and you don’t have missing or unused includes.
include-what-you-use
First, install include-what-you-use. Ubuntu/Debian users can run sudo apt install iwyu and Fedora/RHEL users can run sudo dnf install iwyu. You can then compile VTR with include-what-you-use enabled to get diagnostic messages about includes in all files with the following command:
make CMAKE_PARAMS="-DCMAKE_CXX_INCLUDE_WHAT_YOU_USE=include-what-you-use"
Note that this method checks all source files and the diagnostic messages can be very long.
clangd language server
Alternatively, if your editor supports clangd, you can use it to get diagnostic messages for the specific file you are working with. Visual Studio Code users can use the clangd extension to use clangd instead of Microsoft’s C/C++ extension. To enable include diagnostics, create a file named .clangd in VTR root directory and add the following lines to it:
Diagnostics:
UnusedIncludes: Strict
MissingIncludes: Strict
Running Tests
VTR has a variety of tests which are used to check for correctness, performance and Quality of Result (QoR).
Tests
There are 4 main regression testing suites:
vtr_reg_basic
~1 minute serial
Goal: Fast functionality check
Feature Coverage: Low
Benchmarks: A few small and simple circuits
Architectures: A few simple architectures
This regression test is not suitable for evaluating QoR or performance. Its primary purpose is to make sure the various tools do not crash/fail in the basic VTR flow.
QoR checks in this regression test are primarily ‘canary’ checks to catch gross degradations in QoR. Occasionally, code changes can cause QoR failures (e.g. due to CAD noise – particularly on small benchmarks); usually such failures are not a concern if the QoR differences are small.
vtr_reg_strong
~20 minutes serial, ~15 minutes with -j4
Goal: Broad functionality check
Feature Coverage: High
Benchmarks: A few small circuits, with some special benchmarks to exercise specific features
Architectures: A variety of architectures, including special architectures to exercise specific features
This regression test is not suitable for evaluating QoR or performance. Its primary purpose is try and achieve high functionality coverage.
QoR checks in this regression test are primarily ‘canary’ checks to catch gross degradations in QoR. Occasionally, changes can cause QoR failures (e.g. due to CAD noise – particularly on small benchmarks); usually such failures are not a concern if the QoR differences are small.
vtr_reg_nightly_test1-N
Goal: Most QoR and Performance evaluation
Feature Coverage: Medium
Architectures: A wider variety of architectures
Benchmarks: Small-large size, diverse. Includes:
VTR benchmarks
Titan benchmarks except gaussian_blur (which has the longest run time)
Koios benchmarks
Various special benchmarks and tests for functionality
QoR checks in these regression suites are aimed at evaluating quality and run-time of the VTR flow. As a result any QoR failures are a concern and should be investigated and understood.
Note:
These suites comprise a single large suite,
vtr_reg_nightlyand should be run together to test nightly level regression. They are mostly similar in benchmark coverage interms of size and diversity however each suite tests some unique benchmarks in addition to the VTR benchmarks. Each vtr_reg_nightlysuite runs on a different server (in parallel), so by having N such test suites we speed up CI by a factor of N. Currently the runtime of each suite is capped at 6 hours, so if the runtime exceeds six hours a new vtr_reg_nightly suite (i.e. N+1) should be created.
vtr_reg_weekly
~42 hours with -j4
Goal: Full QoR and Performance evaluation.
Feature Coverage: Medium
Benchmarks: Medium-Large size, diverse. Includes:
VTR benchmarks
Titan23 benchmarks, including gaussian_blur
Architectures: A wide variety of architectures
QoR checks in this regression are aimed at evaluating quality and run-time of the VTR flow. As a result any QoR failures are a concern and should be investigated and understood.
These can be run with run_reg_test.py:
#From the VTR root directory
$ ./run_reg_test.py vtr_reg_basic
$ ./run_reg_test.py vtr_reg_strong
The nightly and weekly regressions require the Titan, ISPD, and Symbiflow benchmarks which can be integrated into your VTR tree with:
$ make get_titan_benchmarks
$ make get_ispd_benchmarks
$ make get_symbiflow_benchmarks
They can then be run using run_reg_test.py:
$ ./run_reg_test.py vtr_reg_nightly_test1
$ ./run_reg_test.py vtr_reg_nightly_test2
$ ./run_reg_test.py vtr_reg_nightly_test3
$ ./run_reg_test.py vtr_reg_weekly
To speed-up things up, individual sub-tests can be run in parallel using the -j option:
#Run up to 4 tests in parallel
$ ./run_reg_test.py vtr_reg_strong -j4
You can also run multiple regression tests together:
#Run both the basic and strong regression, with up to 4 tests in parallel
$ ./run_reg_test.py vtr_reg_basic vtr_reg_strong -j4
Running in a large cluster using SLURM
For the very large runs, you can submit your runs on a large cluster. A template of submission script to a Slurm-managed cluster can be found under vtr_flow/tasks/slurm/
Continuous integration (CI)
Automatic (Github runner) CI tests
For the following tests, you can use remote servers instead of running them locally. Once the changes are pushed into the remote repository, or a PR is created, the Test Workflow will be triggered. Many tests are included in the workflow, including:
odin_reg_strong
parmys_reg_basic
instructions on how to gather QoR results of CI runs can be found here.
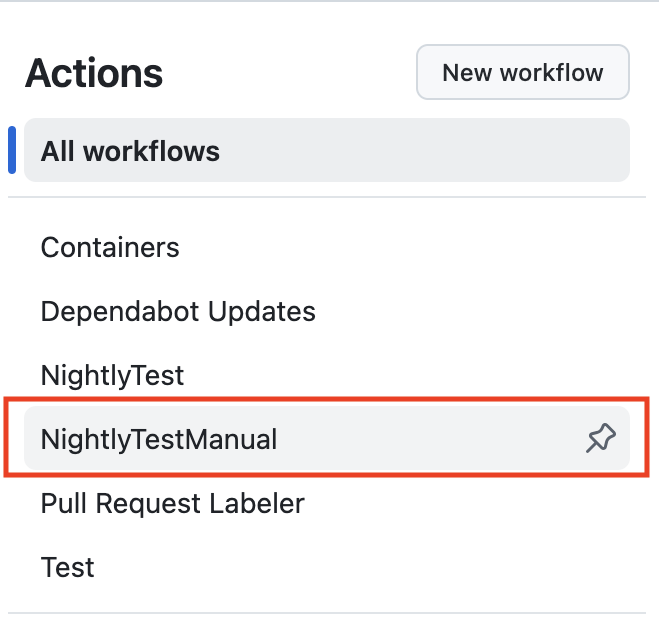
Manual Nightly Tests
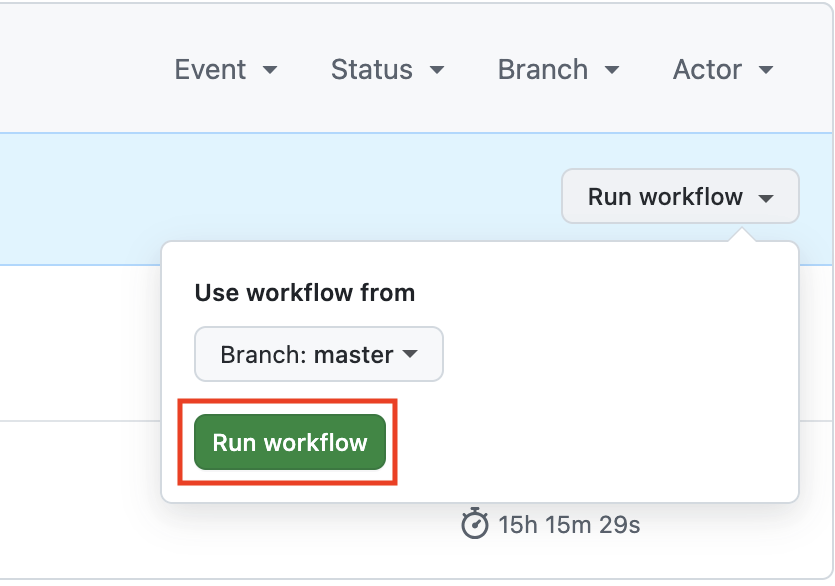
You can use remote servers to run the vtr_reg_nightly_test1-7 tests. These tests are triggered manually by going to the GitHub Actions menu, selecting the NightlyTestManual workflow and selecting run workflow on the branch you want to test. Once you do that, the Nightly Test Manual Workflow will be triggered. This run will take approximately 15 hours to complete and will cancel all other workflow runs for the same branch.
Re-run CI Tests
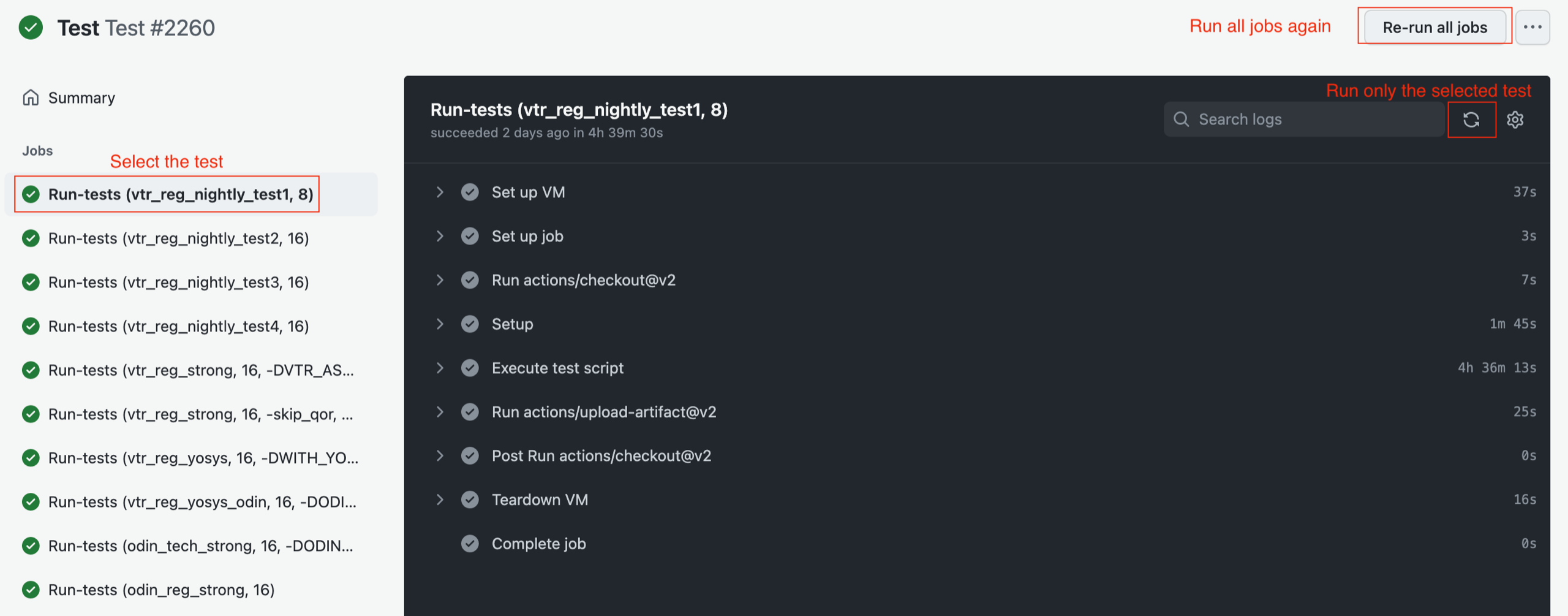
In the case that you want to re-run the CI tests, due to certain issues such as infrastructure failure,
go to the “Action” tab and find your workflow under Test Workflow.
Select the test which you want to re-run. There is a re-run button on the top-right corner of the newly appeared window.
Attention If the previous run is not finished, you will not be able to re-run the CI tests. To circumvent this limitation, there are two options:
Cancel the workflow. After a few minutes, you would be able to re-run the workflow

Wait until the workflow finishes, then re-run the failed jobs
Odin Functionality Tests
Odin has its own set of tests to verify the correctness of its synthesis results:
odin_reg_basic: ~2 minutes serialodin_reg_strong: ~6 minutes serial
These can be run with:
#From the VTR root directory
$ ./run_reg_test.py odin_reg_basic
$ ./run_reg_test.py odin_reg_strong
and should be used when making changes to Odin.
Unit Tests
VTR also has a limited set of unit tests, which can be run with:
#From the VTR root directory
$ make && make test
This will run test_vtrutil, test_vpr, test_fasm, and test_archfpga. Each test suite is added in their CMake
files.
Running Individual Testers
To run one of the four testers listed above on its own, navigate to the appropriate folder:
Test |
Directory |
|---|---|
|
|
|
|
|
|
|
|
To see tester options, run it with -h:
# Using test_vpr as an example
# From $VTR_ROOT/build/vpr
$ ./test_vpr -h
To see the names of each unit test, use --list-tests:
# From $VTR_ROOT/build/vpr
$ ./test_vpr --list-tests
The output should look similar to this:
All available test cases:
test_route_flow
[vpr_noc_bfs_routing]
test_find_block_with_matching_name
[vpr_clustered_netlist]
connection_router
[vpr]
binary_heap
[vpr]
edge_groups_create_sets
[vpr]
read_interchange_models
[vpr]
... # many more test cases
52 test cases
To run specific unit tests, pass them as arguments. For example:
# From $VTR_ROOT/build/vpr
$ ./test_vpr test_route_flow connection_router
Evaluating Quality of Result (QoR) Changes
VTR uses highly tuned and optimized algorithms and data structures. Changes which effect these can have significant impacts on the quality of VTR’s design implementations (timing, area etc.) and VTR’s run-time/memory usage. Such changes need to be evaluated carefully before they are pushed/merged to ensure no quality degradation occurs.
If you are unsure of what level of QoR evaluation is necessary for your changes, please ask a VTR developer for guidance.
General QoR Evaluation Principles
The goal of performing a QoR evaluation is to measure precisely the impact of a set of code/architecture/benchmark changes on both the quality of VTR’s design implementation (i.e. the result of VTR’s optimizations), and on tool run-time and memory usage.
This process is made more challenging by the fact that many of VTR’s optimization algorithms are based on heuristics (some of which depend on randomization). This means that VTR’s implementation results are dependent upon:
The initial conditions (e.g. input architecture & netlist, random number generator seed), and
The precise optimization algorithms used.
The result is that a minor change to either of these can can make the measured QoR change. This effect can be viewed as an intrinsic ‘noise’ or ‘variance’ to any QoR measurement for a particular architecture/benchmark/algorithm combination.
There are typically two key methods used to measure the ‘true’ QoR:
Averaging metrics across multiple architectures and benchmark circuits.
Averaging metrics multiple runs of the same architecture and benchmark, but using different random number generator seeds
This is a further variance reduction technique, although it can be very CPU-time intensive. A typical example would be to sweep an entire benchmark set across 3 or 5 different seeds.
In practice any algorithm changes will likely cause improvements on some architecture/benchmark combinations, and degradations on others. As a result we primarily focus on the average behaviour of a change to evaluate its impact. However extreme outlier behaviour on particular circuits is also important, since it may indicate bugs or other unexpected behaviour.
Key QoR Metrics
The following are key QoR metrics which should be used to evaluate the impact of changes in VTR.
Implementation Quality Metrics:
Metric |
Meaning |
Sensitivity |
|---|---|---|
num_pre_packed_blocks |
Number of primitive netlist blocks (after tech. mapping, before packing) |
Low |
num_post_packed_blocks |
Number of Clustered Blocks (after packing) |
Medium |
device_grid_tiles |
FPGA size in grid tiles |
Low-Medium |
min_chan_width |
The minimum routable channel width |
Medium* |
crit_path_routed_wirelength |
The routed wirelength at the relaxed channel width |
Medium |
NoC_agg_bandwidth** |
The total link bandwidth utilized by all traffic flows |
Low |
NoC_latency** |
The total time of traffic flow data transfer (summed over all traffic flows) |
Low |
NoC_latency_constraints_cost** |
Total number of traffic flows that meet their latency constraints |
Low |
* By default, VPR attempts to find the minimum routable channel width; it then performs routing at a relaxed (e.g. 1.3x minimum) channel width. At minimum channel width routing congestion can distort the true timing/wirelength characteristics. Combined with the fact that most FPGA architectures are built with an abundance of routing, post-routing metrics are usually only evaluated at the relaxed channel width.
** NoC-related metrics are only reported when –noc option is enabled.
Run-time/Memory Usage Metrics:
Metric |
Meaning |
Sensitivity |
|---|---|---|
vtr_flow_elapsed_time |
Wall-clock time to complete the VTR flow |
Low |
pack_time |
Wall-clock time VPR spent during packing |
Low |
place_time |
Wall-clock time VPR spent during placement |
Low |
min_chan_width_route_time |
Wall-clock time VPR spent during routing at the minimum routable channel width |
High* |
crit_path_route_time |
Wall-clock time VPR spent during routing at the relaxed channel width |
Low |
max_vpr_mem |
Maximum memory used by VPR (in kilobytes) |
Low |
* Note that the minimum channel width route time is chaotic and can be highly variable (e.g. 10x variation is not unusual). Minimum channel width routing performs a binary search to find the minimum channel width. Since route time is highly dependent on congestion, run-time is highly dependent on the precise channel widths searched (which may change due to perturbations).
In practice you will likely want to consider additional and more detailed metrics, particularly those directly related to the changes you are making.
For example, if your change related to hold-time optimization you would want to include hold-time related metrics such as hold_TNS (hold total negative slack) and hold_WNS (hold worst negative slack).
If your change related to packing, you would want to report additional packing-related metrics, such as the number of clusters formed by each block type (e.g. numbers of CLBs, RAMs, DSPs, IOs).
Benchmark Selection
An important factor in performing any QoR evaluation is the benchmark set selected. In order to draw reasonably general conclusions about the impact of a change we desire two characteristics of the benchmark set:
It includes a large number of benchmarks which are representative of the application domains of interest.
This ensures we don’t over-tune to a specific benchmark or application domain.
It should include benchmarks of large sizes.
This ensures we can optimize and scale to large problem spaces.
In practice (for various reasons) satisfying both of these goals simultaneously is challenging. The key goal here is to ensure the benchmark set is not unreasonably biased in some manner (e.g. benchmarks which are too small, benchmarks too skewed to a particular application domain).
Fairly measuring tool run-time
Accurately and fairly measuring the run-time of computer programs is challenging in practice. A variety of factors effect run-time including:
Operating System
System load (e.g. other programs running)
Variance in hardware performance (e.g. different CPUs on different machines, CPU frequency scaling)
To make reasonably ‘fair’ run-time comparisons it is important to isolate the change as much as possible from other factors. This involves keeping as much of the experimental environment identical as possible including:
Target benchmarks
Target architecture
Code base (e.g. VTR revision)
CAD parameters
Computer system (e.g. CPU model, CPU frequency/power scaling, OS version)
Compiler version
Collecting QoR Measurements
The first step is to collect QoR metrics on your selected benchmark set.
You need at least two sets of QoR measurements:
The baseline QoR (i.e. unmodified VTR).
The modified QoR (i.e. VTR with your changes).
The following tests can be run locally by running the given commands on the local machine. In addition, since CI tests are run whenever changes are pushed to the remote repository, one can use the CI test results to measure the impact of his/her changes. The instructions to gather CI tests’ results are here.
Note that it is important to generate both sets of QoR measurements on the same computing infrastructure to ensure a fair run-time comparison.
The following examples show how a single set of QoR measurements can be produced using the VTR flow infrastructure.
Example: VTR Benchmarks QoR Measurement
The VTR benchmarks are a group of benchmark circuits distributed with the VTR project. The are provided as synthesizable verilog and can be re-mapped to VTR supported architectures. They consist mostly of small to medium sized circuits from a mix of application domains. They are used primarily to evaluate the VTR’s optimization quality in an architecture exploration/evaluation setting (e.g. determining minimum channel widths).
A typical approach to evaluating an algorithm change would be to run vtr_reg_qor_chain task from the nightly regression test:
#From the VTR root
$ cd vtr_flow/tasks
#Run the VTR benchmarks
$ ../scripts/run_vtr_task.py regression_tests/vtr_reg_nightly_test3/vtr_reg_qor_chain
#Several hours later... they complete
#Parse the results
$ ../scripts/python_libs/vtr/parse_vtr_task.py regression_tests/vtr_reg_nightly_test3/vtr_reg_qor_chain
#The run directory should now contain a summary parse_results.txt file
$ head -5 vtr_reg_nightly_test3/vtr_reg_qor_chain/latest/parse_results.txt
arch circuit script_params vpr_revision vpr_status error num_pre_packed_nets num_pre_packed_blocks num_post_packed_nets num_post_packed_blocks device_width device_height num_clb num_io num_outputs num_memoriesnum_mult placed_wirelength_est placed_CPD_est placed_setup_TNS_est placed_setup_WNS_est min_chan_width routed_wirelength min_chan_width_route_success_iteration crit_path_routed_wirelength crit_path_route_success_iteration critical_path_delay setup_TNS setup_WNS hold_TNS hold_WNS logic_block_area_total logic_block_area_used min_chan_width_routing_area_total min_chan_width_routing_area_per_tile crit_path_routing_area_total crit_path_routing_area_per_tile odin_synth_time abc_synth_time abc_cec_time abc_sec_time ace_time pack_time place_time min_chan_width_route_time crit_path_route_time vtr_flow_elapsed_time max_vpr_mem max_odin_mem max_abc_mem
k6_frac_N10_frac_chain_mem32K_40nm.xml bgm.v common 9f591f6-dirty success 26431 24575 14738 2258 53 53 1958 257 32 0 11 871090 18.5121 -13652.6 -18.5121 84 328781 32 297718 18 20.4406 -15027.8 -20.4406 0 0 1.70873e+08 1.09883e+08 1.63166e+07 5595.54 2.07456e+07 7114.41 11.16 1.03 -1 -1 -1 141.53 108.26 142.42 15.63 652.17 1329712 528868 146796
k6_frac_N10_frac_chain_mem32K_40nm.xml blob_merge.v common 9f591f6-dirty success 14163 11407 3445 700 30 30 564 36 100 0 0 113369 13.4111 -2338.12 -13.4111 64 80075 18 75615 23 15.3479 -2659.17 -15.3479 0 0 4.8774e+07 3.03962e+07 3.87092e+06 4301.02 4.83441e+06 5371.56 0.46 0.17 -1 -1 -1 67.89 11.30 47.60 3.48 198.58 307756 48148 58104
k6_frac_N10_frac_chain_mem32K_40nm.xml boundtop.v common 9f591f6-dirty success 1071 1141 595 389 13 13 55 142 192 0 0 5360 3.2524 -466.039 -3.2524 34 4534 15 3767 12 3.96224 -559.389 -3.96224 0 0 6.63067e+06 2.96417e+06 353000. 2088.76 434699. 2572.18 0.29 0.11 -1 -1 -1 2.55 0.82 2.10 0.15 7.24 87552 38484 37384
k6_frac_N10_frac_chain_mem32K_40nm.xml ch_intrinsics.v common 9f591f6-dirty success 363 493 270 247 10 10 17 99 130 1 0 1792 1.86527 -194.602 -1.86527 46 1562 13 1438 20 2.4542 -226.033 -2.4542 0 0 3.92691e+06 1.4642e+06 259806. 2598.06 333135. 3331.35 0.03 0.01 -1 -1 -1 0.46 0.31 0.94 0.09 2.59 62684 8672 32940
Example: Titan Benchmarks QoR Measurement
The Titan benchmarks are a group of large benchmark circuits from a wide range of applications, which are compatible with the VTR project. The are typically used as post-technology mapped netlists which have been pre-synthesized with Quartus. They are substantially larger and more realistic than the VTR benchmarks, but can only target specifically compatible architectures. They are used primarily to evaluate the optimization quality and scalability of VTR’s CAD algorithms while targeting a fixed architecture (e.g. at a fixed channel width).
A typical approach to evaluating an algorithm change would be to run titan_quick_qor task from the nightly regression test:
Running and Integrating the Titan Benchmarks with VTR
#From the VTR root
#Download and integrate the Titan benchmarks into the VTR source tree
$ make get_titan_benchmarks
#Move to the task directory
$ cd vtr_flow/tasks
#Run the Titan benchmarks
$ ../scripts/run_vtr_task.py regression_tests/vtr_reg_nightly_test2/titan_quick_qor
#Several days later... they complete
#Parse the results
$ ../scripts/python_libs/vtr/parse_vtr_task.py regression_tests/vtr_reg_nightly_test2/titan_quick_qor
#The run directory should now contain a summary parse_results.txt file
$ head -5 vtr_reg_nightly_test2/titan_quick_qor/latest/parse_results.txt
arch circuit vpr_revision vpr_status error num_pre_packed_nets num_pre_packed_blocks num_post_packed_nets num_post_packed_blocks device_width device_height num_clb num_io num_outputs num_memoriesnum_mult placed_wirelength_est placed_CPD_est placed_setup_TNS_est placed_setup_WNS_est routed_wirelength crit_path_route_success_iteration logic_block_area_total logic_block_area_used routing_area_total routing_area_per_tile critical_path_delay setup_TNS setup_WNS hold_TNS hold_WNS pack_time place_time crit_path_route_time max_vpr_mem max_odin_mem max_abc_mem
stratixiv_arch.timing.xml neuron_stratixiv_arch_timing.blif 0208312 success 119888 86875 51408 3370 128 95 -1 42 35 -1 -1 3985635 8.70971 -234032 -8.70971 1086419 20 0 0 2.66512e+08 21917.1 9.64877 -262034 -9.64877 0 0 127.92 218.48 259.96 5133800 -1 -1
stratixiv_arch.timing.xml sparcT1_core_stratixiv_arch_timing.blif 0208312 success 92813 91974 54564 4170 77 57 -1 173 137 -1 -1 3213593 7.87734 -534295 -7.87734 1527941 43 0 0 9.64428e+07 21973.8 9.06977 -625483 -9.06977 0 0 327.38 338.65 364.46 3690032 -1 -1
stratixiv_arch.timing.xml stereo_vision_stratixiv_arch_timing.blif 0208312 success 127088 94088 62912 3776 128 95 -1 326 681 -1 -1 4875541 8.77339 -166097 -8.77339 998408 16 0 0 2.66512e+08 21917.1 9.36528 -187552 -9.36528 0 0 110.03 214.16 189.83 5048580 -1 -1
stratixiv_arch.timing.xml cholesky_mc_stratixiv_arch_timing.blif 0208312 success 140214 108592 67410 5444 121 90 -1 111 151 -1 -1 5221059 8.16972 -454610 -8.16972 1518597 15 0 0 2.38657e+08 21915.3 9.34704 -531231 -9.34704 0 0 211.12 364.32 490.24 6356252 -1 -1
Example: NoC Benchmarks QoR Measurements
NoC benchmarks currently include synthetic and MLP benchmarks. Synthetic benchmarks have various NoC traffic patterns, bandwidth utilization, and latency requirements. High-quality NoC router placement solutions for these benchmarks are known. By comparing the known solutions with NoC router placement results, the developer can evaluate the sanity of the NoC router placement algorithm. MLP benchmarks are the only realistic netlists included in this benchmark set.
Based on the number of NoC routers in a synthetic benchmark, it is run on one of two different architectures. All MLP benchmarks are run on an FPGA architecture with 16 NoC routers. Post-technology mapped netlists (blif files) for synthetic benchmarks are added to the VTR project. However, MLP blif files are very large and should be downloaded separately.
Since NoC benchmarks target different FPGA architectures, they are run as different circuits. A typical way to run all NoC benchmarks is to run a task list and gather QoR data form different tasks:
Running and Integrating the NoC Benchmarks with VTR
#From the VTR root
#Download and integrate NoC MLP benchmarks into the VTR source tree
$ make get_noc_mlp_benchmarks
#Move to the task directory
$ cd vtr_flow
#Run the VTR benchmarks
$ scripts/run_vtr_task.py -l tasks/noc_qor/task_list.txt
#Several days later... they complete
#NoC benchmarks are run as several different tasks. Therefore, QoR results should be gathered from multiple directories,
#one for each task.
$ head -5 tasks/noc_qor/large_complex_synthetic/latest/parse_results.txt
$ head -5 tasks/noc_qor/large_simple_synthetic/latest/parse_results.txt
$ head -5 tasks/noc_qor/small_complex_synthetic/latest/parse_results.txt
$ head -5 tasks/noc_qor/small_simple_synthetic/latest/parse_results.txt
$ head -5 tasks/noc_qor/MLP/latest/parse_results.txt
Example: Koios Benchmarks QoR Measurement
The Koios benchmarks are a group of Deep Learning benchmark circuits distributed with the VTR project. The are provided as synthesizable verilog and can be re-mapped to VTR supported architectures. They consist mostly of medium to large sized circuits from Deep Learning (DL). They can be used for FPGA architecture exploration for DL and also for tuning CAD tools.
A typical approach to evaluating an algorithm change would be to run koios_medium (or koios_medium_no_hb) tasks from the nightly regression test (vtr_reg_nightly_test4), the koios_large (or koios_large_no_hb) and the koios_proxy (or koios_proxy_no_hb) tasks from the weekly regression test (vtr_reg_weekly). The nightly test contains smaller benchmarks, whereas the large designs are in the weekly regression test. To measure QoR for the entire benchmark suite, both nightly and weekly tests should be run and the results should be concatenated.
As 3 of the koios_large circuits require special settings due to having long DSP chains, they are split in separate tasks as follows:
bwave_like.float.large.vandbwave_like.fixed.large.vare invtr_reg_weekly/koios_bwave_largetaskdla_like.large.vis invtr_reg_weekly/koios_dla_largetask
For evaluating an algorithm change in the Odin frontend, run koios_medium (or koios_medium_no_hb) tasks from the nightly regression test (vtr_reg_nightly_test4_odin) and the koios_large_odin (or koios_large_no_hb_odin) tasks from the weekly regression test (vtr_reg_weekly).
The koios_medium, koios_large, and koios_proxy regression tasks run these benchmarks with complex_dsp functionality enabled, whereas koios_medium_no_hb, koios_large_no_hb and koios_proxy_no_hb regression tasks run these benchmarks without complex_dsp functionality. Normally, only the koios_medium, koios_large, and koios_proxy tasks should be enough for QoR.
The koios_sv and koios_sv_no_hb tasks utilize the System-Verilog parser in the Parmys frontend.
The following table provides details on available Koios settings in VTR flow:
Suite |
Test Description |
Target |
Complex DSP Features |
Config file |
Frontend |
Parser |
|---|---|---|---|---|---|---|
Nightly |
Medium designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
✓ |
vtr_reg_nightly_test4/koios_medium |
Parmys |
|
Nightly |
Medium designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
vtr_reg_nightly_test4/koios_medium_no_hb |
Parmys |
||
Nightly |
Medium designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
✓ |
vtr_reg_nightly_test4_odin/koios_medium |
Odin |
|
Nightly |
Medium designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
vtr_reg_nightly_test4_odin/koios_medium_no_hb |
Odin |
||
Weekly |
Large designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
✓ |
vtr_reg_weekly/koios_large |
Parmys |
|
Weekly |
Large designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
✓ |
vtr_reg_weekly/koios_dla_large |
Parmys |
|
Weekly |
Large designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
✓ |
vtr_reg_weekly/koios_bwave_large |
Parmys |
|
Weekly |
Large designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
vtr_reg_weekly/koios_large_no_hb |
Parmys |
||
Weekly |
Large designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
✓ |
vtr_reg_weekly/koios_large_odin |
Odin |
|
Weekly |
Large designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
vtr_reg_weekly/koios_large_no_hb_odin |
Odin |
||
Weekly |
Proxy designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
✓ |
vtr_reg_weekly/koios_proxy |
Parmys |
|
Weekly |
Proxy designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
vtr_reg_weekly/koios_proxy_no_hb |
Parmys |
||
Weekly |
deepfreeze designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
✓ |
vtr_reg_weekly/koios_sv |
Parmys |
System-Verilog |
Weekly |
deepfreeze designs |
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml |
vtr_reg_weekly/koios_sv_no_hb |
Parmys |
System-Verilog |
For more information refer to the Koios benchmark home page.
To make running all the koios benchmarks easier, especially with those circuits scattered between different tasks, there is an overall task list that runs all the 40 circuits of Koios as follows (this will run all the circuits with complex DSP functionality enabled. If you want to disable the complex DSP, edit the file to point to the koios_*_no_hb tasks):
$ ../scripts/run_vtr_task.py -l koios_task_list.txt
#Several hours later... they complete
#
If you want to run a subset of the koios benchmarks or run them without hard DSP blocks, you can run lower-level 'koios' tasks as follows:
```shell
#From the VTR root
$ cd vtr_flow/tasks
#Choose any config file from the table above and run the Koios benchmarks, for example:
$ ../scripts/run_vtr_task.py regression_tests/vtr_reg_nightly_test4/koios_medium &
$ ../scripts/run_vtr_task.py regression_tests/vtr_reg_weekly/koios_large &
$ ../scripts/run_vtr_task.py regression_tests/vtr_reg_weekly/koios_proxy &
$ ../scripts/run_vtr_task.py regression_tests/vtr_reg_weekly/koios_sv &
#Disable hard blocks (hard_mem and complex_dsp macros) to verify memory and generic hard blocks inference:
$ ../scripts/run_vtr_task.py regression_tests/vtr_reg_nightly_test4/koios_medium_no_hb &
$ ../scripts/run_vtr_task.py regression_tests/vtr_reg_weekly/koios_large_no_hb &
$ ../scripts/run_vtr_task.py regression_tests/vtr_reg_weekly/koios_proxy_no_hb &
$ ../scripts/run_vtr_task.py regression_tests/vtr_reg_weekly/koios_sv_no_hb &
#Several hours later... they complete
#The run directory should now contain a summary parse_results.txt file
$ head -5 vtr_reg_nightly_test4/koios_medium/<latest_run_dir>/parse_results.txt
arch circuit script_params vtr_flow_elapsed_time vtr_max_mem_stage vtr_max_mem error odin_synth_time max_odin_mem parmys_synth_time max_parmys_mem abc_depth abc_synth_time abc_cec_time abc_sec_time max_abc_mem ace_time max_ace_mem num_clb num_io num_memories num_mult vpr_status vpr_revision vpr_build_info vpr_compiler vpr_compiled hostname rundir max_vpr_mem num_primary_inputs num_primary_outputs num_pre_packed_nets num_pre_packed_blocks num_netlist_clocks num_post_packed_nets num_post_packed_blocks device_width device_height device_grid_tiles device_limiting_resources device_name pack_mem pack_time placed_wirelength_est place_mem place_time place_quench_time placed_CPD_est placed_setup_TNS_est placed_setup_WNS_est placed_geomean_nonvirtual_intradomain_critical_path_delay_est place_delay_matrix_lookup_time place_quench_timing_analysis_time place_quench_sta_time place_total_timing_analysis_time place_total_sta_time min_chan_width routed_wirelength min_chan_width_route_success_iteration logic_block_area_total logic_block_area_used min_chan_width_routing_area_total min_chan_width_routing_area_per_tile min_chan_width_route_time min_chan_width_total_timing_analysis_time min_chan_width_total_sta_time crit_path_routed_wirelength crit_path_route_success_iteration crit_path_total_nets_routed crit_path_total_connections_routed crit_path_total_heap_pushes crit_path_total_heap_pops critical_path_delay geomean_nonvirtual_intradomain_critical_path_delay setup_TNS setup_WNS hold_TNS hold_WNS crit_path_routing_area_total crit_path_routing_area_per_tile router_lookahead_computation_time crit_path_route_time crit_path_total_timing_analysis_time crit_path_total_sta_time
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml tpu_like.small.os.v common 677.72 vpr 2.29 GiB -1 -1 19.40 195276 5 99.61 -1 -1 109760 -1 -1 492 355 32 -1 success 327aa1d-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.10.35-v8 x86_64 2023-02-09T16:01:10 gh-actions-runner-vtr-auto-spawned87 /root/vtr-verilog-to-routing/vtr-verilog-to-routing 2400616 355 289 25429 18444 2 12313 1433 136 136 18496 dsp_top auto 208.3 MiB 14.61 359754 2344.4 MiB 16.75 0.18 5.12303 -82671.4 -5.12303 2.1842 6.09 0.0412666 0.0368158 6.35102 5.65512 -1 394367 16 5.92627e+08 8.53857e+07 4.08527e+08 22087.3 4.50 8.69097 7.85207 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml tpu_like.small.ws.v common 722.22 vpr 2.30 GiB -1 -1 23.09 242848 5 72.60 -1 -1 117236 -1 -1 686 357 58 -1 success 327aa1d-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.10.35-v8 x86_64 2023-02-09T16:01:10 gh-actions-runner-vtr-auto-spawned87 /root/vtr-verilog-to-routing/vtr-verilog-to-routing 2415672 357 289 25686 20353 2 12799 1656 136 136 18496 dsp_top auto 233.3 MiB 98.40 226648 2359.1 MiB 20.07 0.17 8.31923 -74283.8 -8.31923 2.78336 6.05 0.0420585 0.0356747 6.53862 5.54952 -1 293644 13 5.92627e+08 9.4632e+07 4.08527e+08 22087.3 4.58 8.69976 7.55132 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml dla_like.small.v common 2800.18 vpr 1.75 GiB -1 -1 94.38 736748 6 754.09 -1 -1 389988 -1 -1 3895 206 132 -1 success 327aa1d-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.10.35-v8 x86_64 2023-02-09T16:01:10 gh-actions-runner-vtr-auto-spawned87 /root/vtr-verilog-to-routing/vtr-verilog-to-routing 1840088 206 13 165036 139551 1 69732 4358 88 88 7744 dsp_top auto 1052.4 MiB 1692.76 601396 1606.1 MiB 88.48 0.64 5.30279 -150931 -5.30279 5.30279 1.96 0.131322 0.104184 16.7561 13.7761 -1 876475 15 2.4541e+08 1.55281e+08 1.69370e+08 21871.2 14.42 24.7943 21.0377 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml bnn.v common 797.74 vpr 2.01 GiB -1 -1 84.28 729308 3 56.57 -1 -1 411036 -1 -1 6190 260 0 -1 success 327aa1d-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.10.35-v8 x86_64 2023-02-09T16:01:10 gh-actions-runner-vtr-auto-spawned87 /root/vtr-verilog-to-routing/vtr-verilog-to-routing 2106860 260 122 206251 154342 1 87361 6635 87 87 7569 clb auto 1300.8 MiB 202.79 910701 1723.3 MiB 174.17 1.12 6.77966 -140235 -6.77966 6.77966 1.97 0.198989 0.175034 29.926 24.7241 -1 1199797 17 2.37162e+08 1.88714e+08 1.65965e+08 21927.0 20.72 41.872 35.326 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
$ head -5 vtr_reg_weekly/koios_large/<latest_run_dir>/parse_results.txt
arch circuit script_params vtr_flow_elapsed_time vtr_max_mem_stage vtr_max_mem error odin_synth_time max_odin_mem parmys_synth_time max_parmys_mem abc_depth abc_synth_time abc_cec_time abc_sec_time max_abc_mem ace_time max_ace_mem num_clb num_io num_memories num_mult vpr_status vpr_revision vpr_build_info vpr_compiler vpr_compiled hostname rundir max_vpr_mem num_primary_inputs num_primary_outputs num_pre_packed_nets num_pre_packed_blocks num_netlist_clocks num_post_packed_nets num_post_packed_blocks device_width device_height device_grid_tiles device_limiting_resources device_name pack_mem pack_time placed_wirelength_est total_swap accepted_swap rejected_swap aborted_swap place_mem place_time place_quench_time placed_CPD_est placed_setup_TNS_est placed_setup_WNS_est placed_geomean_nonvirtual_intradomain_critical_path_delay_est place_delay_matrix_lookup_time place_quench_timing_analysis_time place_quench_sta_time place_total_timing_analysis_time place_total_sta_time min_chan_width routed_wirelength min_chan_width_route_success_iteration logic_block_area_total logic_block_area_used min_chan_width_routing_area_total min_chan_width_routing_area_per_tile min_chan_width_route_time min_chan_width_total_timing_analysis_time min_chan_width_total_sta_time crit_path_num_rr_graph_nodes crit_path_num_rr_graph_edges crit_path_collapsed_nodes crit_path_routed_wirelength crit_path_route_success_iteration crit_path_total_nets_routed crit_path_total_connections_routed crit_path_total_heap_pushes crit_path_total_heap_pops critical_path_delay geomean_nonvirtual_intradomain_critical_path_delay setup_TNS setup_WNS hold_TNS hold_WNS crit_path_routing_area_total crit_path_routing_area_per_tile router_lookahead_computation_time crit_path_route_time crit_path_create_rr_graph_time crit_path_create_intra_cluster_rr_graph_time crit_path_tile_lookahead_computation_time crit_path_router_lookahead_computation_time crit_path_total_timing_analysis_time crit_path_total_sta_time
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml lenet.v common 6320.39 parmys 6.81 GiB -1 -1 2279.37 7141128 8 3659.89 -1 -1 229600 -1 -1 1215 3 0 -1 success 9c0df2e-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-03T14:49:57 mustang /homes/vtr-verilog-to-routing 406996 3 73 29130 23346 1 13644 1292 40 40 1600 clb auto 246.6 MiB 64.06 136280 627318 185500 408250 33568 357.7 MiB 81.14 0.66 8.27929 -16089.3 -8.27929 8.27929 1.10 0.16804 0.146992 16.9432 13.6451 -1 224227 19 4.87982e+07 3.41577e+07 3.42310e+07 21394.3 19.75 26.6756 21.8374 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml clstm_like.small.v common 11605.17 vpr 3.24 GiB -1 -1 669.16 1080564 4 7868.39 -1 -1 606244 -1 -1 7733 652 237 -1 success 9c0df2e-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-03T14:49:57 mustang /homes/vtr-verilog-to-routing 3400468 652 290 299247 274102 1 72966 9121 120 120 14400 dsp_top auto 1946.1 MiB 741.62 1061263 13535473 5677109 7516142 342222 3001.0 MiB 915.91 6.25 6.0577 -397722 -6.0577 6.0577 16.74 1.09797 0.908781 169.318 135.356 -1 1289121 17 4.60155e+08 3.01448e+08 3.17281e+08 22033.4 108.23 234.326 190.185 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml clstm_like.medium.v common 42560.88 vpr 6.35 GiB -1 -1 1060.82 2104648 4 35779.24 -1 -1 1168924 -1 -1 15289 652 458 -1 success 9c0df2e-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-03T14:49:57 mustang /homes/vtr-verilog-to-routing 6658128 652 578 587833 538751 1 142046 17388 168 168 28224 dsp_top auto 3792.2 MiB 1334.50 2402446 32440572 13681743 17973716 785113 5856.8 MiB 1927.66 10.89 6.9964 -921673 -6.9964 6.9964 34.97 2.51671 1.97649 373.17 302.896 -1 2735850 16 9.07771e+08 5.93977e+08 6.21411e+08 22017.1 228.75 493.742 407.089 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml clstm_like.large.v common 79534.09 vpr 9.24 GiB -1 -1 1581.99 3213072 4 69583.96 -1 -1 1763048 -1 -1 22846 652 679 -1 success 9c0df2e-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-03T14:49:57 mustang /homes/vtr-verilog-to-routing 9688232 652 866 876458 803425 1 211260 25656 200 200 40000 dsp_top auto 5580.4 MiB 2073.77 4237568 55245338 23267923 30805131 1172284 8437.3 MiB 2868.84 15.36 8.07111 -1.60215e+06 -8.07111 8.07111 54.87 2.67554 2.06921 438.894 351.141 -1 4656710 14 1.28987e+09 8.86534e+08 8.79343e+08 21983.6 469.61 576.631 470.505 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
$ head -5 vtr_reg_weekly/koios_proxy/<latest_run_dir>/parse_results.txt
arch circuit script_params vtr_flow_elapsed_time vtr_max_mem_stage vtr_max_mem error odin_synth_time max_odin_mem parmys_synth_time max_parmys_mem abc_depth abc_synth_time abc_cec_time abc_sec_time max_abc_mem ace_time max_ace_mem num_clb num_io num_memories num_mult vpr_status vpr_revision vpr_build_info vpr_compiler vpr_compiled hostname rundir max_vpr_mem num_primary_inputs num_primary_outputs num_pre_packed_nets num_pre_packed_blocks num_netlist_clocks num_post_packed_nets num_post_packed_blocks device_width device_height device_grid_tiles device_limiting_resources device_name pack_mem pack_time placed_wirelength_est total_swap accepted_swap rejected_swap aborted_swap place_mem place_time place_quench_time placed_CPD_est placed_setup_TNS_est placed_setup_WNS_est placed_geomean_nonvirtual_intradomain_critical_path_delay_est place_delay_matrix_lookup_time place_quench_timing_analysis_time place_quench_sta_time place_total_timing_analysis_time place_total_sta_time min_chan_width routed_wirelength min_chan_width_route_success_iteration logic_block_area_total logic_block_area_used min_chan_width_routing_area_total min_chan_width_routing_area_per_tile min_chan_width_route_time min_chan_width_total_timing_analysis_time min_chan_width_total_sta_time crit_path_num_rr_graph_nodes crit_path_num_rr_graph_edges crit_path_collapsed_nodes crit_path_routed_wirelength crit_path_route_success_iteration crit_path_total_nets_routed crit_path_total_connections_routed crit_path_total_heap_pushes crit_path_total_heap_pops critical_path_delay geomean_nonvirtual_intradomain_critical_path_delay setup_TNS setup_WNS hold_TNS hold_WNS crit_path_routing_area_total crit_path_routing_area_per_tile router_lookahead_computation_time crit_path_route_time crit_path_create_rr_graph_time crit_path_create_intra_cluster_rr_graph_time crit_path_tile_lookahead_computation_time crit_path_router_lookahead_computation_time crit_path_total_timing_analysis_time crit_path_total_sta_time
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml proxy.1.v common 30535.22 vpr 9.48 GiB -1 -1 1652.38 3799616 7 2393.26 -1 -1 771680 -1 -1 5817 938 845 -1 success 909f29c-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-08T17:55:38 mustang /homes/vtr-verilog-to-routing 9940848 938 175 262404 208705 1 137273 8816 264 264 69696 dsp_top auto 1962.1 MiB 17465.99 3242084 14209964 6064078 7558347 587539 9707.9 MiB 2269.49 11.20 8.49902 -576590 -8.49902 8.49902 120.99 1.65144 1.34401 319.238 263.953 -1 4269357 15 2.25492e+09 5.42827e+08 1.53035e+09 21957.6 291.49 414.451 348.422 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml proxy.2.v common 49383.26 parmys 7.46 GiB -1 -1 6711.91 7820216 8 22879.15 -1 -1 1478720 -1 -1 8948 318 1105 -1 success 909f29c-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-08T17:55:38 mustang /homes/vtr-verilog-to-routing 6046424 318 256 373725 328044 1 148054 10957 188 188 35344 memory auto 2466.3 MiB 15021.62 2653372 16311253 6713874 9344147 253232 5904.7 MiB 1439.25 8.76 7.35195 -768561 -7.35195 7.35195 47.97 1.45054 1.22978 225.237 181.257 -1 3431386 18 1.1352e+09 4.85551e+08 7.77871e+08 22008.6 262.44 314.625 258.401 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml proxy.3.v common 19852.09 vpr 4.44 GiB -1 -1 2415.20 2344724 9 11508.95 -1 -1 604164 -1 -1 9318 732 846 -1 success 909f29c-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-08T17:55:38 mustang /homes/vtr-verilog-to-routing 4650536 732 304 284977 256401 1 127990 11307 164 164 26896 memory auto 2050.2 MiB 1517.07 1834702 15487251 6133696 9051915 301640 4541.5 MiB 1750.28 13.38 9.89252 -499927 -9.89252 9.89252 33.45 1.83357 1.60237 215.923 175.904 -1 2500777 18 8.6211e+08 4.03628e+08 5.92859e+08 22042.6 191.91 301.651 247.975 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
$ head -5 vtr_reg_weekly/koios_sv/<latest_run_dir>/parse_results.txt
arch circuit script_params vtr_flow_elapsed_time vtr_max_mem_stage vtr_max_mem error odin_synth_time max_odin_mem parmys_synth_time max_parmys_mem abc_depth abc_synth_time abc_cec_time abc_sec_time max_abc_mem ace_time max_ace_mem num_clb num_io num_memories num_mult vpr_status vpr_revision vpr_build_info vpr_compiler vpr_compiled hostname rundir max_vpr_mem num_primary_inputs num_primary_outputs num_pre_packed_nets num_pre_packed_blocks num_netlist_clocks num_post_packed_nets num_post_packed_blocks device_width device_height device_grid_tiles device_limiting_resources device_name pack_mem pack_time placed_wirelength_est total_swap accepted_swap rejected_swap aborted_swap place_mem place_time place_quench_time placed_CPD_est placed_setup_TNS_est placed_setup_WNS_est placed_geomean_nonvirtual_intradomain_critical_path_delay_est place_delay_matrix_lookup_time place_quench_timing_analysis_time place_quench_sta_time place_total_timing_analysis_time place_total_sta_time min_chan_width routed_wirelength min_chan_width_route_success_iteration logic_block_area_total logic_block_area_used min_chan_width_routing_area_total min_chan_width_routing_area_per_tile min_chan_width_route_time min_chan_width_total_timing_analysis_time min_chan_width_total_sta_time crit_path_num_rr_graph_nodes crit_path_num_rr_graph_edges crit_path_collapsed_nodes crit_path_routed_wirelength crit_path_route_success_iteration crit_path_total_nets_routed crit_path_total_connections_routed crit_path_total_heap_pushes crit_path_total_heap_pops critical_path_delay geomean_nonvirtual_intradomain_critical_path_delay setup_TNS setup_WNS hold_TNS hold_WNS crit_path_routing_area_total crit_path_routing_area_per_tile router_lookahead_computation_time crit_path_route_time crit_path_create_rr_graph_time crit_path_create_intra_cluster_rr_graph_time crit_path_tile_lookahead_computation_time crit_path_router_lookahead_computation_time crit_path_total_timing_analysis_time crit_path_total_sta_time
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml deepfreeze.style1.sv common 22714.73 vpr 4.09 GiB -1 -1 949.56 2651192 3 16835.50 -1 -1 1290132 -1 -1 12293 27 396 -1 success 377bca3-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-13T17:58:15 mustang /homes/sv-deep 4288252 27 513 420409 319910 1 173122 13274 122 122 14884 clb auto 2706.3 MiB 2229.92 358719 32218159 15492330 11108513 5617316 3575.6 MiB 1036.24 4.96 4.77742 -203483 -4.77742 4.77742 16.43 1.44734 1.24291 322.276 265.06 -1 525106 18 4.7523e+08 4.08959e+08 3.28149e+08 22047.1 89.42 403.175 333.904 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml deepfreeze.style2.sv common 24680.43 vpr 14.80 GiB -1 -1 827.06 2325884 3 11919.13 -1 -1 1064952 -1 -1 8475 6 140 -1 success 377bca3-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-13T17:58:15 mustang /homes/sv-deep 15515036 6 513 281129 194945 1 142714 10896 338 338 114244 dsp_top auto 2163.1 MiB 2308.76 1873008 23434650 9090338 12891091 1453221 15151.4 MiB 1246.22 10.86 11.0869 -410426 -11.0869 11.0869 189.96 1.47102 1.33008 298.642 263.028 -1 2267430 14 3.68993e+09 7.02925e+08 2.50989e+09 21969.6 104.21 368.851 326.754 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml deepfreeze.style3.sv common 9459.64 parmys 2.59 GiB -1 -1 1046.45 2716236 3 5554.19 -1 -1 1151548 -1 -1 4951 27 115 -1 success 377bca3-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-13T17:58:15 mustang /homes/sv-deep 2669896 27 513 162561 120322 1 71039 5820 120 120 14400 dsp_top auto 1254.2 MiB 874.69 253375 9948140 4723336 3618748 1606056 2607.3 MiB 379.75 1.99 5.71612 -91795.4 -5.71612 5.71612 14.90 0.558622 0.482091 114.978 97.3208 -1 365131 15 4.60155e+08 2.08293e+08 3.17281e+08 22033.4 34.50 143.778 122.884 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
$ head -5 vtr_reg_nightly_test4/koios_medium_no_hb/<latest_run_dir>/parse_results.txt
arch circuit script_params vtr_flow_elapsed_time vtr_max_mem_stage vtr_max_mem error odin_synth_time max_odin_mem parmys_synth_time max_parmys_mem abc_depth abc_synth_time abc_cec_time abc_sec_time max_abc_mem ace_time max_ace_mem num_clb num_io num_memories num_mult vpr_status vpr_revision vpr_build_info vpr_compiler vpr_compiled hostname rundir max_vpr_mem num_primary_inputs num_primary_outputs num_pre_packed_nets num_pre_packed_blocks num_netlist_clocks num_post_packed_nets num_post_packed_blocks device_width device_height device_grid_tiles device_limiting_resources device_name pack_mem pack_time placed_wirelength_est total_swap accepted_swap rejected_swap aborted_swap place_mem place_time place_quench_time placed_CPD_est placed_setup_TNS_est placed_setup_WNS_est placed_geomean_nonvirtual_intradomain_critical_path_delay_est place_delay_matrix_lookup_time place_quench_timing_analysis_time place_quench_sta_time place_total_timing_analysis_time place_total_sta_time min_chan_width routed_wirelength min_chan_width_route_success_iteration logic_block_area_total logic_block_area_used min_chan_width_routing_area_total min_chan_width_routing_area_per_tile min_chan_width_route_time min_chan_width_total_timing_analysis_time min_chan_width_total_sta_time crit_path_num_rr_graph_nodes crit_path_num_rr_graph_edges crit_path_collapsed_nodes crit_path_routed_wirelength crit_path_route_success_iteration crit_path_total_nets_routed crit_path_total_connections_routed crit_path_total_heap_pushes crit_path_total_heap_pops critical_path_delay geomean_nonvirtual_intradomain_critical_path_delay setup_TNS setup_WNS hold_TNS hold_WNS crit_path_routing_area_total crit_path_routing_area_per_tile router_lookahead_computation_time crit_path_route_time crit_path_create_rr_graph_time crit_path_create_intra_cluster_rr_graph_time crit_path_tile_lookahead_computation_time crit_path_router_lookahead_computation_time crit_path_total_timing_analysis_time crit_path_total_sta_time
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml tpu_like.small.os.v common 2297.73 vpr 2.39 GiB -1 -1 67.66 248916 5 386.57 -1 -1 139588 -1 -1 1092 355 32 -1 success 9550a0d release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-12T17:44:41 mustang /homes/koios 2505488 355 289 47792 39479 2 22463 2033 136 136 18496 dsp_top auto 315.6 MiB 829.80 417547 2035967 800879 1110613 124475 2446.8 MiB 59.61 0.36 7.56032 -98878.8 -7.56032 2.65337 18.45 0.123782 0.101211 21.3991 17.4955 -1 526122 14 5.92627e+08 1.02128e+08 4.08527e+08 22087.3 15.74 27.6882 23.1868 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml tpu_like.small.ws.v common 2034.94 vpr 2.43 GiB -1 -1 56.02 302204 5 517.89 -1 -1 139816 -1 -1 1447 357 58 -1 success 9550a0d release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-12T17:44:41 mustang /homes/koios 2549132 357 289 56236 49095 2 21896 2417 136 136 18496 dsp_top auto 393.4 MiB 344.10 429105 2548015 930606 1466225 151184 2489.4 MiB 85.48 0.50 7.79199 -137248 -7.79199 2.69372 18.37 0.163784 0.137256 28.7844 22.9255 -1 558155 17 5.92627e+08 1.15867e+08 4.08527e+08 22087.3 23.93 38.6761 31.6913 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml dla_like.small.v common 8355.37 vpr 1.83 GiB -1 -1 172.77 753612 6 2243.64 -1 -1 412976 -1 -1 4119 206 132 -1 success 9550a0d release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-12T17:44:41 mustang /homes/koios 1920604 206 13 177171 148374 1 74857 4582 88 88 7744 dsp_top auto 1112.1 MiB 5121.00 676743 4607543 1735144 2771118 101281 1657.7 MiB 309.31 2.26 6.5785 -161896 -6.5785 6.5785 6.26 0.492287 0.382534 63.1824 50.6687 -1 975264 23 2.4541e+08 1.61532e+08 1.69370e+08 21871.2 57.11 95.977 78.7754 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml bnn.v common 1618.20 vpr 2.03 GiB -1 -1 148.99 734288 3 121.88 -1 -1 410764 -1 -1 6192 260 0 -1 success 9550a0d release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-12T17:44:41 mustang /homes/koios 2131528 260 122 206267 154358 1 87325 6637 87 87 7569 clb auto 1304.8 MiB 399.50 897507 7862107 3019050 4332770 510287 1741.6 MiB 424.98 3.12 6.46586 -141256 -6.46586 6.46586 5.97 0.627132 0.490712 79.1961 63.5977 -1 1180668 18 2.37162e+08 1.8877e+08 1.65965e+08 21927.0 60.49 113.428 92.6149 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
$ head -5 vtr_reg_weekly/koios_large_no_hb/<latest_run_dir>/parse_results.txt
arch circuit script_params vtr_flow_elapsed_time vtr_max_mem_stage vtr_max_mem error odin_synth_time max_odin_mem parmys_synth_time max_parmys_mem abc_depth abc_synth_time abc_cec_time abc_sec_time max_abc_mem ace_time max_ace_mem num_clb num_io num_memories num_mult vpr_status vpr_revision vpr_build_info vpr_compiler vpr_compiled hostname rundir max_vpr_mem num_primary_inputs num_primary_outputs num_pre_packed_nets num_pre_packed_blocks num_netlist_clocks num_post_packed_nets num_post_packed_blocks device_width device_height device_grid_tiles device_limiting_resources device_name pack_mem pack_time placed_wirelength_est total_swap accepted_swap rejected_swap aborted_swap place_mem place_time place_quench_time placed_CPD_est placed_setup_TNS_est placed_setup_WNS_est placed_geomean_nonvirtual_intradomain_critical_path_delay_est place_delay_matrix_lookup_time place_quench_timing_analysis_time place_quench_sta_time place_total_timing_analysis_time place_total_sta_time min_chan_width routed_wirelength min_chan_width_route_success_iteration logic_block_area_total logic_block_area_used min_chan_width_routing_area_total min_chan_width_routing_area_per_tile min_chan_width_route_time min_chan_width_total_timing_analysis_time min_chan_width_total_sta_time crit_path_num_rr_graph_nodes crit_path_num_rr_graph_edges crit_path_collapsed_nodes crit_path_routed_wirelength crit_path_route_success_iteration crit_path_total_nets_routed crit_path_total_connections_routed crit_path_total_heap_pushes crit_path_total_heap_pops critical_path_delay geomean_nonvirtual_intradomain_critical_path_delay setup_TNS setup_WNS hold_TNS hold_WNS crit_path_routing_area_total crit_path_routing_area_per_tile router_lookahead_computation_time crit_path_route_time crit_path_create_rr_graph_time crit_path_create_intra_cluster_rr_graph_time crit_path_tile_lookahead_computation_time crit_path_router_lookahead_computation_time crit_path_total_timing_analysis_time crit_path_total_sta_time
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml lenet.v common 6512.03 parmys 6.81 GiB -1 -1 2803.15 7141204 8 3272.22 -1 -1 229632 -1 -1 1215 3 0 -1 success 9c0df2e-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-03T14:49:57 mustang /homes/vtr-verilog-to-routing 406888 3 73 29130 23346 1 13644 1292 40 40 1600 clb auto 246.5 MiB 63.14 136280 627318 185500 408250 33568 357.6 MiB 85.00 0.86 8.27929 -16089.3 -8.27929 8.27929 1.13 0.12917 0.113598 13.8302 11.3301 -1 224227 19 4.87982e+07 3.41577e+07 3.42310e+07 21394.3 19.69 22.8327 18.7232 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml clstm_like.small.v common 17199.48 vpr 3.24 GiB -1 -1 583.78 1084852 4 13572.40 -1 -1 606412 -1 -1 7731 652 237 -1 success 9c0df2e-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-03T14:49:57 mustang /homes/vtr-verilog-to-routing 3400564 652 290 299239 274094 1 72874 9119 120 120 14400 dsp_top auto 1946.4 MiB 725.17 1086525 13721951 5750436 7628104 343411 3000.6 MiB 920.88 5.92 6.3706 -404576 -6.3706 6.3706 16.00 1.30631 1.07494 208.425 167.37 -1 1308179 19 4.60155e+08 3.01393e+08 3.17281e+08 22033.4 125.07 285.633 232.404 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml clstm_like.medium.v common 44836.58 vpr 6.35 GiB -1 -1 1206.67 2108616 4 37270.70 -1 -1 1168924 -1 -1 15290 652 460 -1 success 9c0df2e-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-03T14:49:57 mustang /homes/vtr-verilog-to-routing 6654212 652 578 587830 538748 1 142127 17391 168 168 28224 dsp_top auto 3784.4 MiB 1272.33 2541145 33348915 14048448 18476269 824198 5852.2 MiB 2378.39 15.56 6.83162 -1.04508e+06 -6.83162 6.83162 36.38 2.58887 2.22298 379.541 301.913 -1 2865108 16 9.07771e+08 5.9428e+08 6.21411e+08 22017.1 283.80 506.773 410.065 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml clstm_like.large.v common 79425.36 vpr 9.26 GiB -1 -1 1997.66 3183680 4 68911.59 -1 -1 1763240 -1 -1 22848 652 682 -1 success 9c0df2e-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-03T14:49:57 mustang /homes/vtr-verilog-to-routing 9708760 652 866 876471 803438 1 211268 25661 200 200 40000 dsp_top auto 5596.5 MiB 2037.93 4249390 55259651 23005638 31099607 1154406 8453.4 MiB 2762.94 28.11 7.65321 -1.56393e+06 -7.65321 7.65321 50.04 2.65623 2.07346 405.053 322.505 -1 4619796 15 1.28987e+09 8.87003e+08 8.79343e+08 21983.6 963.02 568.098 461.604 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
$ head -5 vtr_reg_weekly/koios_proxy_no_hb/<latest_run_dir>/parse_results.txt
arch circuit script_params vtr_flow_elapsed_time vtr_max_mem_stage vtr_max_mem error odin_synth_time max_odin_mem parmys_synth_time max_parmys_mem abc_depth abc_synth_time abc_cec_time abc_sec_time max_abc_mem ace_time max_ace_mem num_clb num_io num_memories num_mult vpr_status vpr_revision vpr_build_info vpr_compiler vpr_compiled hostname rundir max_vpr_mem num_primary_inputs num_primary_outputs num_pre_packed_nets num_pre_packed_blocks num_netlist_clocks num_post_packed_nets num_post_packed_blocks device_width device_height device_grid_tiles device_limiting_resources device_name pack_mem pack_time placed_wirelength_est total_swap accepted_swap rejected_swap aborted_swap place_mem place_time place_quench_time placed_CPD_est placed_setup_TNS_est placed_setup_WNS_est placed_geomean_nonvirtual_intradomain_critical_path_delay_est place_delay_matrix_lookup_time place_quench_timing_analysis_time place_quench_sta_time place_total_timing_analysis_time place_total_sta_time min_chan_width routed_wirelength min_chan_width_route_success_iteration logic_block_area_total logic_block_area_used min_chan_width_routing_area_total min_chan_width_routing_area_per_tile min_chan_width_route_time min_chan_width_total_timing_analysis_time min_chan_width_total_sta_time crit_path_num_rr_graph_nodes crit_path_num_rr_graph_edges crit_path_collapsed_nodes crit_path_routed_wirelength crit_path_route_success_iteration crit_path_total_nets_routed crit_path_total_connections_routed crit_path_total_heap_pushes crit_path_total_heap_pops critical_path_delay geomean_nonvirtual_intradomain_critical_path_delay setup_TNS setup_WNS hold_TNS hold_WNS crit_path_routing_area_total crit_path_routing_area_per_tile router_lookahead_computation_time crit_path_route_time crit_path_create_rr_graph_time crit_path_create_intra_cluster_rr_graph_time crit_path_tile_lookahead_computation_time crit_path_router_lookahead_computation_time crit_path_total_timing_analysis_time crit_path_total_sta_time
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml proxy.1.v common 30535.22 vpr 9.48 GiB -1 -1 1652.38 3799616 7 2393.26 -1 -1 771680 -1 -1 5817 938 845 -1 success 909f29c-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-08T17:55:38 mustang /homes/vtr-verilog-to-routing 9940848 938 175 262404 208705 1 137273 8816 264 264 69696 dsp_top auto 1962.1 MiB 17465.99 3242084 14209964 6064078 7558347 587539 9707.9 MiB 2269.49 11.20 8.49902 -576590 -8.49902 8.49902 120.99 1.65144 1.34401 319.238 263.953 -1 4269357 15 2.25492e+09 5.42827e+08 1.53035e+09 21957.6 291.49 414.451 348.422 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml proxy.2.v common 49383.26 parmys 7.46 GiB -1 -1 6711.91 7820216 8 22879.15 -1 -1 1478720 -1 -1 8948 318 1105 -1 success 909f29c-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-08T17:55:38 mustang /homes/vtr-verilog-to-routing 6046424 318 256 373725 328044 1 148054 10957 188 188 35344 memory auto 2466.3 MiB 15021.62 2653372 16311253 6713874 9344147 253232 5904.7 MiB 1439.25 8.76 7.35195 -768561 -7.35195 7.35195 47.97 1.45054 1.22978 225.237 181.257 -1 3431386 18 1.1352e+09 4.85551e+08 7.77871e+08 22008.6 262.44 314.625 258.401 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml proxy.3.v common 19852.09 vpr 4.44 GiB -1 -1 2415.20 2344724 9 11508.95 -1 -1 604164 -1 -1 9318 732 846 -1 success 909f29c-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-08T17:55:38 mustang /homes/vtr-verilog-to-routing 4650536 732 304 284977 256401 1 127990 11307 164 164 26896 memory auto 2050.2 MiB 1517.07 1834702 15487251 6133696 9051915 301640 4541.5 MiB 1750.28 13.38 9.89252 -499927 -9.89252 9.89252 33.45 1.83357 1.60237 215.923 175.904 -1 2500777 18 8.6211e+08 4.03628e+08 5.92859e+08 22042.6 191.91 301.651 247.975 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml proxy.4.v common 54152.82 parmys 8.16 GiB -1 -1 5711.77 8560300 7 7695.81 -1 -1 1228588 -1 -1 7685 546 1085 -1 success 909f29c-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-08T17:55:38 mustang /homes/vtr-verilog-to-routing 7638244 546 1846 328200 285098 1 145315 11924 222 222 49284 dsp_top auto 2318.8 MiB 34102.96 3359643 20028032 8510897 11052028 465107 7459.2 MiB 2454.78 12.61 9.3047 -839575 -9.3047 9.3047 72.17 2.37032 2.07569 353.073 294.754 -1 4470327 15 1.58612e+09 5.57186e+08 1.08358e+09 21986.5 321.00 457.912 387.485 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
$ head -5 vtr_reg_weekly/koios_sv_no_hb/<latest_run_dir>/parse_results.txt
arch circuit script_params vtr_flow_elapsed_time vtr_max_mem_stage vtr_max_mem error odin_synth_time max_odin_mem parmys_synth_time max_parmys_mem abc_depth abc_synth_time abc_cec_time abc_sec_time max_abc_mem ace_time max_ace_mem num_clb num_io num_memories num_mult vpr_status vpr_revision vpr_build_info vpr_compiler vpr_compiled hostname rundir max_vpr_mem num_primary_inputs num_primary_outputs num_pre_packed_nets num_pre_packed_blocks num_netlist_clocks num_post_packed_nets num_post_packed_blocks device_width device_height device_grid_tiles device_limiting_resources device_name pack_mem pack_time placed_wirelength_est total_swap accepted_swap rejected_swap aborted_swap place_mem place_time place_quench_time placed_CPD_est placed_setup_TNS_est placed_setup_WNS_est placed_geomean_nonvirtual_intradomain_critical_path_delay_est place_delay_matrix_lookup_time place_quench_timing_analysis_time place_quench_sta_time place_total_timing_analysis_time place_total_sta_time min_chan_width routed_wirelength min_chan_width_route_success_iteration logic_block_area_total logic_block_area_used min_chan_width_routing_area_total min_chan_width_routing_area_per_tile min_chan_width_route_time min_chan_width_total_timing_analysis_time min_chan_width_total_sta_time crit_path_num_rr_graph_nodes crit_path_num_rr_graph_edges crit_path_collapsed_nodes crit_path_routed_wirelength crit_path_route_success_iteration crit_path_total_nets_routed crit_path_total_connections_routed crit_path_total_heap_pushes crit_path_total_heap_pops critical_path_delay geomean_nonvirtual_intradomain_critical_path_delay setup_TNS setup_WNS hold_TNS hold_WNS crit_path_routing_area_total crit_path_routing_area_per_tile router_lookahead_computation_time crit_path_route_time crit_path_create_rr_graph_time crit_path_create_intra_cluster_rr_graph_time crit_path_tile_lookahead_computation_time crit_path_router_lookahead_computation_time crit_path_total_timing_analysis_time crit_path_total_sta_time
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml deepfreeze.style1.sv common 47967.94 vpr 10.31 GiB -1 -1 1750.70 3477528 3 33798.52 -1 -1 1967140 -1 -1 20253 27 1843 -1 success 377bca3-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-13T17:58:15 mustang /homes/sv-deep 10811692 27 513 778797 600279 1 384107 23186 244 244 59536 memory auto 4968.5 MiB 3724.68 4867625 48601541 21188063 25604799 1808679 10366.4 MiB 3892.48 41.19 8.46401 -1.13947e+06 -8.46401 8.46401 82.35 2.83854 2.28574 443.492 355.56 -1 5791588 17 1.92066e+09 9.58441e+08 1.30834e+09 21975.7 419.89 594.451 484.887 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml deepfreeze.style2.sv common 48524.73 vpr 8.29 GiB -1 -1 1440.31 3118316 3 35219.69 -1 -1 1725016 -1 -1 22674 27 1231 -1 success 377bca3-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-13T17:58:15 mustang /homes/sv-deep 8696204 27 513 757966 564979 1 371413 24999 196 196 38416 memory auto 4726.6 MiB 2712.89 5184470 52271336 22299033 27769653 2202650 7642.4 MiB 5209.27 55.51 9.75062 -937734 -9.75062 9.75062 50.02 2.30465 1.94566 366.253 293.69 -1 6516523 17 1.23531e+09 9.4276e+08 8.45266e+08 22003.0 925.98 493.024 402.412 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
k6FracN10LB_mem20K_complexDSP_customSB_22nm.xml deepfreeze.style3.sv common 41631.02 vpr 15.22 GiB -1 -1 1622.97 3431784 3 24896.76 -1 -1 1856148 -1 -1 20779 27 3333 -1 success 377bca3-dirty release IPO VTR_ASSERT_LEVEL=2 GNU 9.4.0 on Linux-5.4.0-148-generic x86_64 2023-12-13T17:58:15 mustang /homes/sv-deep 15958564 27 513 703297 547641 1 350325 24854 324 324 104976 memory auto 4656.9 MiB 3861.23 5201129 61655974 26414908 31818866 3422200 15584.5 MiB 3575.85 19.40 9.71561 -1.53645e+06 -9.71561 9.71561 179.24 2.62795 2.23108 484.893 395.834 -1 6173057 19 3.39753e+09 1.08992e+09 2.30538e+09 21961.0 377.21 640.096 530.51 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
Example: Extracting QoR Data from CI Runs
Instead of running tests/designs locally to generate QoR data, you can also extract the QoR data from any of the standard test runs performed automatically by CI on a pull request. To get the QoR results of the above tests, go to the “Action” tab. On the menu on the left, choose “Test” and select your workflow. If running the tests is done, scroll down and click on “artifact”. This would download the results for all CI tests.
Go to “Action” tab

Select “Test” and choose your workflow
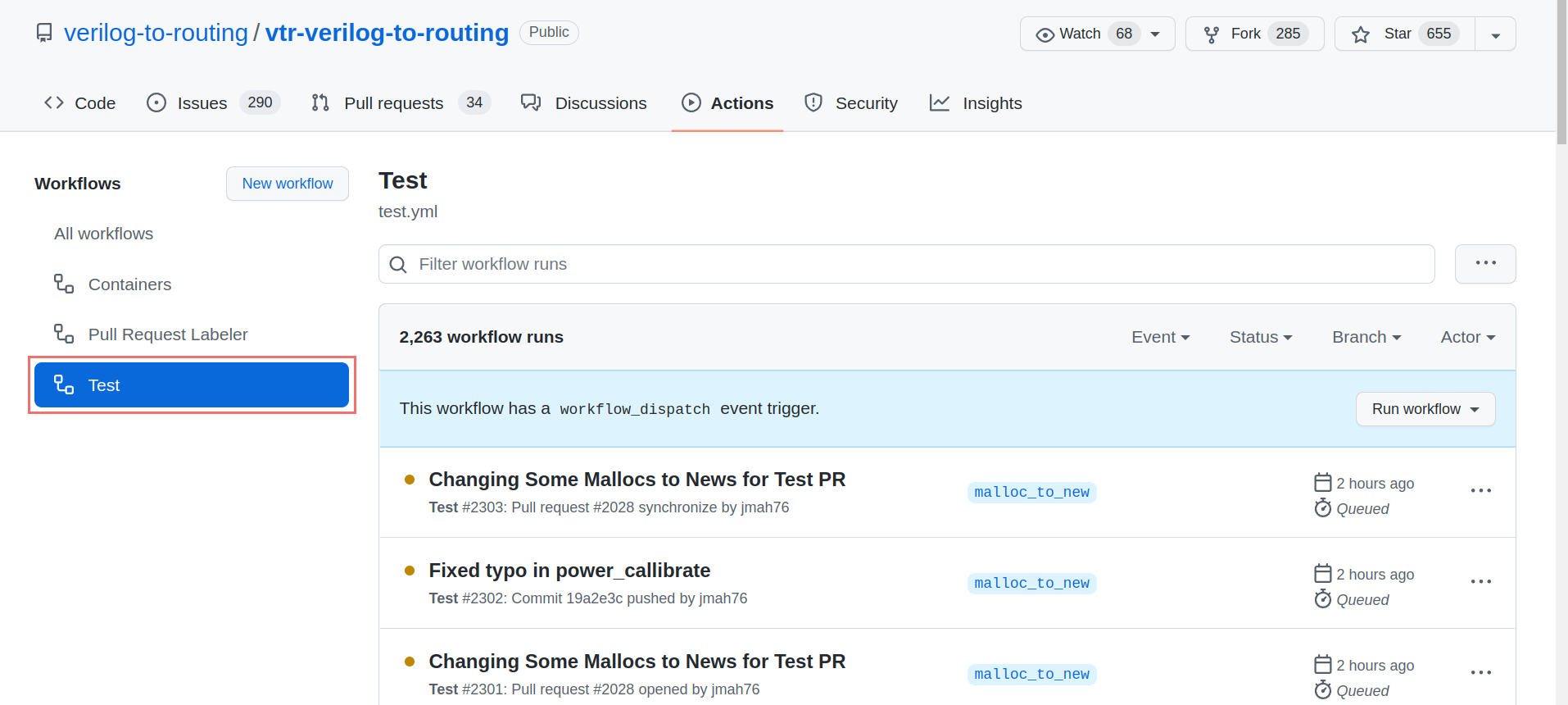
Scroll down and download “artifact”
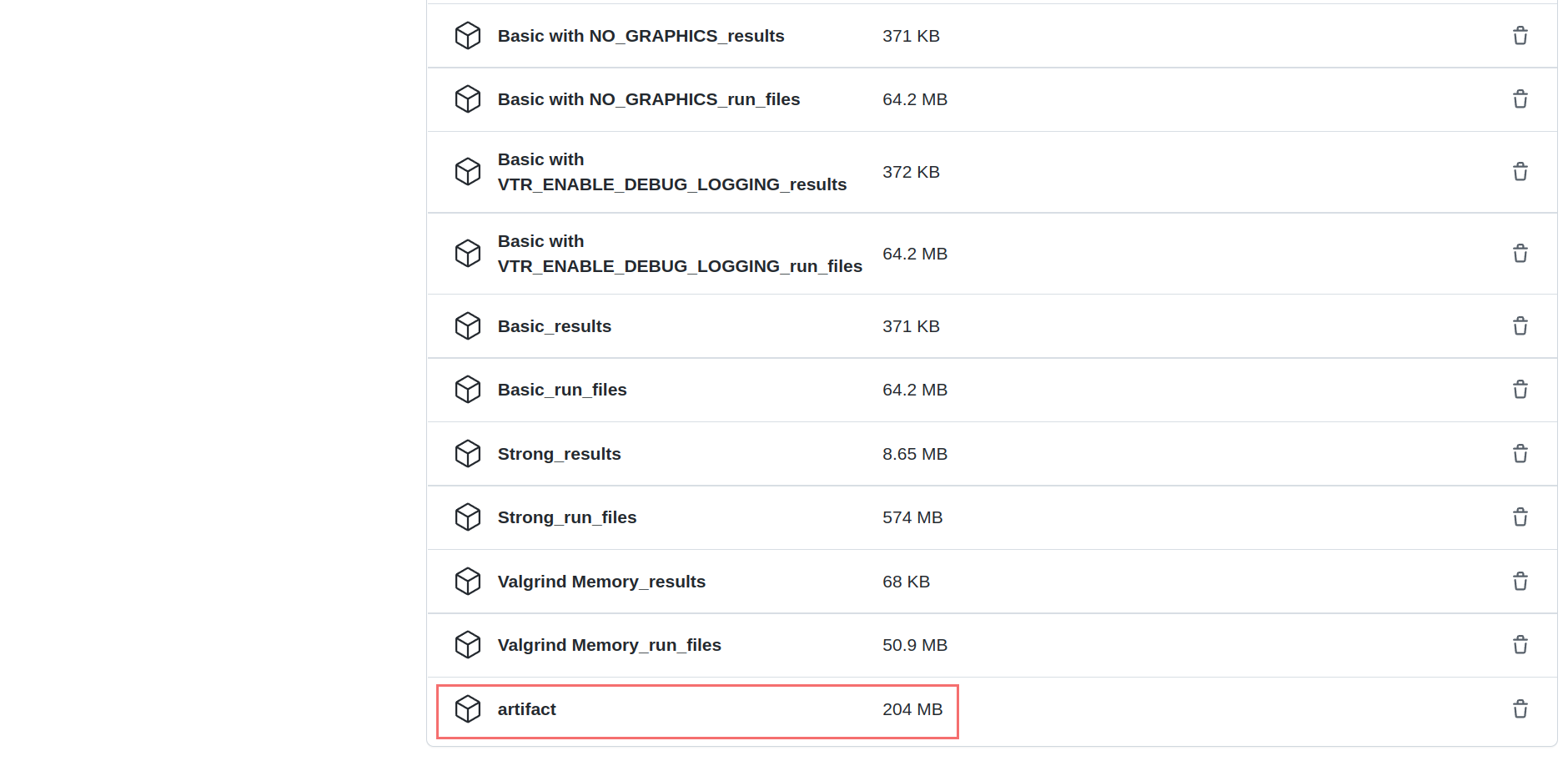
Assume that we want to get the QoR results for “vtr_reg_nightly_test3”. In the artifact, there is a file named
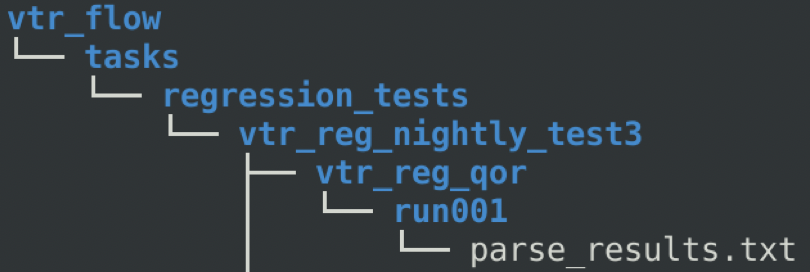
“qor_results_vtr_reg_nightly_test3.tar.gz.” Unzip this file, and a new directory named “vtr_flow” is created. Go to
“vtr_flow/tasks/regression_tests/vtr_reg_nightly_test3.” In this directory, you can find a directory for each benchmark
contained in this test suite (vtr_reg_nightly_test3.) In the directory for each sub-test, there is another directory
named run001. Two files are here: qor_results.txt, and parse_results.txt. QoR results for all circuits tested in this
benchmark are stored in these files.
Using these parsed results, you can do a detailed QoR comparison using the instructions given here.
Comparing QoR Measurements
Once you have two (or more) sets of QoR measurements they now need to be compared.
A general method is as follows:
Normalize all metrics to the values in the baseline measurements (this makes the relative changes easy to evaluate)
Produce tables for each set of QoR measurements showing the per-benchmark relative values for each metric
Calculate the GEOMEAN over all benchmarks for each normalized metric
Produce a summary table showing the Metric Geomeans for each set of QoR measurements
QoR Comparison Gotchas
There are a variety of ‘gotchas’ you need to avoid to ensure fair comparisons:
GEOMEAN’s must be over the same set of benchmarks . A common issue is that a benchmark failed to complete for some reason, and it’s metric values are missing
Run-times need to be collected on the same compute infrastructure at the same system load (ideally unloaded).
Example QoR Comparison
Suppose we’ve make a change to VTR, and we now want to evaluate the change. As described above we produce QoR measurements for both the VTR baseline, and our modified version.
We then have the following (hypothetical) QoR Metrics.
Baseline QoR Metrics:
arch |
circuit |
num_pre_packed_blocks |
num_post_packed_blocks |
device_grid_tiles |
min_chan_width |
crit_path_routed_wirelength |
critical_path_delay |
vtr_flow_elapsed_time |
pack_time |
place_time |
min_chan_width_route_time |
crit_path_route_time |
max_vpr_mem |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
k6_frac_N10_frac_chain_mem32K_40nm.xml |
bgm.v |
24575 |
2258 |
2809 |
84 |
297718 |
20.4406 |
652.17 |
141.53 |
108.26 |
142.42 |
15.63 |
1329712 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
blob_merge.v |
11407 |
700 |
900 |
64 |
75615 |
15.3479 |
198.58 |
67.89 |
11.3 |
47.6 |
3.48 |
307756 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
boundtop.v |
1141 |
389 |
169 |
34 |
3767 |
3.96224 |
7.24 |
2.55 |
0.82 |
2.1 |
0.15 |
87552 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
ch_intrinsics.v |
493 |
247 |
100 |
46 |
1438 |
2.4542 |
2.59 |
0.46 |
0.31 |
0.94 |
0.09 |
62684 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
diffeq1.v |
886 |
313 |
256 |
60 |
9624 |
17.9648 |
15.59 |
2.45 |
1.36 |
9.93 |
0.93 |
86524 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
diffeq2.v |
599 |
201 |
256 |
52 |
8928 |
13.7083 |
13.14 |
1.41 |
0.87 |
9.14 |
0.94 |
85760 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
LU8PEEng.v |
31396 |
2286 |
2916 |
100 |
348085 |
79.4512 |
1514.51 |
175.67 |
153.01 |
1009.08 |
45.47 |
1410872 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
LU32PEEng.v |
101542 |
7251 |
9216 |
158 |
1554942 |
80.062 |
28051.68 |
625.03 |
930.58 |
25050.73 |
251.87 |
4647936 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mcml.v |
165809 |
6767 |
8649 |
128 |
1311825 |
51.1905 |
9088.1 |
524.8 |
742.85 |
4001.03 |
127.42 |
4999124 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mkDelayWorker32B.v |
4145 |
1327 |
2500 |
38 |
30086 |
8.39902 |
65.54 |
7.73 |
15.39 |
26.19 |
3.23 |
804720 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mkPktMerge.v |
1160 |
516 |
784 |
44 |
13370 |
4.4408 |
21.75 |
2.45 |
2.14 |
13.95 |
1.96 |
122872 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mkSMAdapter4B.v |
2852 |
548 |
400 |
48 |
19274 |
5.26765 |
47.64 |
16.22 |
4.16 |
19.95 |
1.14 |
116012 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
or1200.v |
4530 |
1321 |
729 |
62 |
51633 |
9.67406 |
105.62 |
33.37 |
12.93 |
44.95 |
3.33 |
219376 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
raygentop.v |
2934 |
710 |
361 |
58 |
22045 |
5.14713 |
39.72 |
9.54 |
4.06 |
19.8 |
2.34 |
126056 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
sha.v |
3024 |
236 |
289 |
62 |
16653 |
10.0144 |
390.89 |
11.47 |
2.7 |
6.18 |
0.75 |
117612 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision0.v |
21801 |
1122 |
1156 |
58 |
64935 |
3.63177 |
82.74 |
20.45 |
15.49 |
24.5 |
2.6 |
411884 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision1.v |
19538 |
1096 |
1600 |
100 |
143517 |
5.61925 |
272.41 |
26.99 |
18.15 |
149.46 |
15.49 |
676844 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision2.v |
42078 |
2534 |
7396 |
134 |
650583 |
15.3151 |
3664.98 |
66.72 |
119.26 |
3388.7 |
62.6 |
3114880 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision3.v |
324 |
55 |
49 |
30 |
768 |
2.66429 |
2.25 |
0.75 |
0.2 |
0.57 |
0.05 |
61148 |
Modified QoR Metrics:
arch |
circuit |
num_pre_packed_blocks |
num_post_packed_blocks |
device_grid_tiles |
min_chan_width |
crit_path_routed_wirelength |
critical_path_delay |
vtr_flow_elapsed_time |
pack_time |
place_time |
min_chan_width_route_time |
crit_path_route_time |
max_vpr_mem |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
k6_frac_N10_frac_chain_mem32K_40nm.xml |
bgm.v |
24575 |
2193 |
2809 |
82 |
303891 |
20.414 |
642.01 |
70.09 |
113.58 |
198.09 |
16.27 |
1222072 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
blob_merge.v |
11407 |
684 |
900 |
72 |
77261 |
14.6676 |
178.16 |
34.31 |
13.38 |
57.89 |
3.35 |
281468 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
boundtop.v |
1141 |
369 |
169 |
40 |
3465 |
3.5255 |
4.48 |
1.13 |
0.7 |
0.9 |
0.17 |
82912 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
ch_intrinsics.v |
493 |
241 |
100 |
54 |
1424 |
2.50601 |
1.75 |
0.19 |
0.27 |
0.43 |
0.09 |
60796 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
diffeq1.v |
886 |
293 |
256 |
50 |
9972 |
17.3124 |
15.24 |
0.69 |
0.97 |
11.27 |
1.44 |
72204 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
diffeq2.v |
599 |
187 |
256 |
50 |
7621 |
13.1714 |
14.14 |
0.63 |
1.04 |
10.93 |
0.78 |
68900 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
LU8PEEng.v |
31396 |
2236 |
2916 |
98 |
349074 |
77.8611 |
1269.26 |
88.44 |
153.25 |
843.31 |
49.13 |
1319276 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
LU32PEEng.v |
101542 |
6933 |
9216 |
176 |
1700697 |
80.1368 |
28290.01 |
306.21 |
897.95 |
25668.4 |
278.74 |
4224048 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mcml.v |
165809 |
6435 |
8649 |
124 |
1240060 |
45.6693 |
9384.4 |
296.99 |
686.27 |
4782.43 |
99.4 |
4370788 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mkDelayWorker32B.v |
4145 |
1207 |
2500 |
36 |
33354 |
8.3986 |
53.94 |
3.85 |
14.75 |
19.53 |
2.95 |
785316 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mkPktMerge.v |
1160 |
494 |
784 |
36 |
13881 |
4.57189 |
20.75 |
0.82 |
1.97 |
15.01 |
1.88 |
117636 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mkSMAdapter4B.v |
2852 |
529 |
400 |
56 |
19817 |
5.21349 |
27.58 |
5.05 |
2.66 |
14.65 |
1.11 |
103060 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
or1200.v |
4530 |
1008 |
729 |
76 |
48034 |
8.70797 |
202.25 |
10.1 |
8.31 |
171.96 |
2.86 |
178712 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
raygentop.v |
2934 |
634 |
361 |
58 |
20799 |
5.04571 |
22.58 |
2.75 |
2.42 |
12.86 |
1.64 |
108116 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
sha.v |
3024 |
236 |
289 |
62 |
16052 |
10.5007 |
337.19 |
5.32 |
2.25 |
4.52 |
0.69 |
105948 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision0.v |
21801 |
1121 |
1156 |
58 |
70046 |
3.61684 |
86.5 |
9.5 |
15.02 |
41.81 |
2.59 |
376100 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision1.v |
19538 |
1080 |
1600 |
92 |
142805 |
6.02319 |
343.83 |
10.68 |
16.21 |
247.99 |
11.66 |
480352 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision2.v |
42078 |
2416 |
7396 |
124 |
646793 |
14.6606 |
5614.79 |
34.81 |
107.66 |
5383.58 |
62.27 |
2682976 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision3.v |
324 |
54 |
49 |
34 |
920 |
2.5281 |
1.55 |
0.31 |
0.14 |
0.43 |
0.05 |
63444 |
Based on these metrics we then calculate the following ratios and summary.
QoR Metric Ratio (Modified QoR / Baseline QoR):
arch |
circuit |
num_pre_packed_blocks |
num_post_packed_blocks |
device_grid_tiles |
min_chan_width |
crit_path_routed_wirelength |
critical_path_delay |
vtr_flow_elapsed_time |
pack_time |
place_time |
min_chan_width_route_time |
crit_path_route_time |
max_vpr_mem |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
k6_frac_N10_frac_chain_mem32K_40nm.xml |
bgm.v |
1.00 |
0.97 |
1.00 |
0.98 |
1.02 |
1.00 |
0.98 |
0.50 |
1.05 |
1.39 |
1.04 |
0.92 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
blob_merge.v |
1.00 |
0.98 |
1.00 |
1.13 |
1.02 |
0.96 |
0.90 |
0.51 |
1.18 |
1.22 |
0.96 |
0.91 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
boundtop.v |
1.00 |
0.95 |
1.00 |
1.18 |
0.92 |
0.89 |
0.62 |
0.44 |
0.85 |
0.43 |
1.13 |
0.95 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
ch_intrinsics.v |
1.00 |
0.98 |
1.00 |
1.17 |
0.99 |
1.02 |
0.68 |
0.41 |
0.87 |
0.46 |
1.00 |
0.97 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
diffeq1.v |
1.00 |
0.94 |
1.00 |
0.83 |
1.04 |
0.96 |
0.98 |
0.28 |
0.71 |
1.13 |
1.55 |
0.83 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
diffeq2.v |
1.00 |
0.93 |
1.00 |
0.96 |
0.85 |
0.96 |
1.08 |
0.45 |
1.20 |
1.20 |
0.83 |
0.80 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
LU8PEEng.v |
1.00 |
0.98 |
1.00 |
0.98 |
1.00 |
0.98 |
0.84 |
0.50 |
1.00 |
0.84 |
1.08 |
0.94 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
LU32PEEng.v |
1.00 |
0.96 |
1.00 |
1.11 |
1.09 |
1.00 |
1.01 |
0.49 |
0.96 |
1.02 |
1.11 |
0.91 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mcml.v |
1.00 |
0.95 |
1.00 |
0.97 |
0.95 |
0.89 |
1.03 |
0.57 |
0.92 |
1.20 |
0.78 |
0.87 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mkDelayWorker32B.v |
1.00 |
0.91 |
1.00 |
0.95 |
1.11 |
1.00 |
0.82 |
0.50 |
0.96 |
0.75 |
0.91 |
0.98 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mkPktMerge.v |
1.00 |
0.96 |
1.00 |
0.82 |
1.04 |
1.03 |
0.95 |
0.33 |
0.92 |
1.08 |
0.96 |
0.96 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
mkSMAdapter4B.v |
1.00 |
0.97 |
1.00 |
1.17 |
1.03 |
0.99 |
0.58 |
0.31 |
0.64 |
0.73 |
0.97 |
0.89 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
or1200.v |
1.00 |
0.76 |
1.00 |
1.23 |
0.93 |
0.90 |
1.91 |
0.30 |
0.64 |
3.83 |
0.86 |
0.81 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
raygentop.v |
1.00 |
0.89 |
1.00 |
1.00 |
0.94 |
0.98 |
0.57 |
0.29 |
0.60 |
0.65 |
0.70 |
0.86 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
sha.v |
1.00 |
1.00 |
1.00 |
1.00 |
0.96 |
1.05 |
0.86 |
0.46 |
0.83 |
0.73 |
0.92 |
0.90 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision0.v |
1.00 |
1.00 |
1.00 |
1.00 |
1.08 |
1.00 |
1.05 |
0.46 |
0.97 |
1.71 |
1.00 |
0.91 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision1.v |
1.00 |
0.99 |
1.00 |
0.92 |
1.00 |
1.07 |
1.26 |
0.40 |
0.89 |
1.66 |
0.75 |
0.71 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision2.v |
1.00 |
0.95 |
1.00 |
0.93 |
0.99 |
0.96 |
1.53 |
0.52 |
0.90 |
1.59 |
0.99 |
0.86 |
k6_frac_N10_frac_chain_mem32K_40nm.xml |
stereovision3.v |
1.00 |
0.98 |
1.00 |
1.13 |
1.20 |
0.95 |
0.69 |
0.41 |
0.70 |
0.75 |
1.00 |
1.04 |
GEOMEAN |
1.00 |
0.95 |
1.00 |
1.02 |
1.01 |
0.98 |
0.92 |
0.42 |
0.87 |
1.03 |
0.96 |
0.89 |
QoR Summary:
baseline |
modified |
|
|---|---|---|
num_pre_packed_blocks |
1.00 |
1.00 |
num_post_packed_blocks |
1.00 |
0.95 |
device_grid_tiles |
1.00 |
1.00 |
min_chan_width |
1.00 |
1.02 |
crit_path_routed_wirelength |
1.00 |
1.01 |
critical_path_delay |
1.00 |
0.98 |
vtr_flow_elapsed_time |
1.00 |
0.92 |
pack_time |
1.00 |
0.42 |
place_time |
1.00 |
0.87 |
min_chan_width_route_time |
1.00 |
1.03 |
crit_path_route_time |
1.00 |
0.96 |
max_vpr_mem |
1.00 |
0.89 |
From the results we can see that our change, on average, achieved a small reduction in the number of logic blocks (0.95) in return for a 2% increase in minimum channel width and 1% increase in routed wirelength. From a run-time perspective the packer is substantially faster (0.42).
Automated QoR Comparison Script
To automate some of the QoR comparison VTR includes a script to compare parse_results.txt files and generate a spreadsheet including the ratio and summary tables.
For example:
#From the VTR Root
$ ./vtr_flow/scripts/qor_compare.py parse_results1.txt parse_results2.txt parse_results3.txt -o comparison.xlsx
will produce ratio tables and a summary table for the files parse_results1.txt, parse_results2.txt and parse_results3.txt, where the first file (parse_results1.txt) is assumed to be the baseline used to produce normalized ratios.
Generating New QoR Golden Result
There may be times when a regression test fails its QoR test because its golden_result needs to be changed due to known changes in code behaviour. In this case, a new golden result needs to be generated so that the test can be passed. To generate a new golden result, follow the steps outlined below.
Move to the
vtr_flow/tasksdirectory from the VTR root, and run the failing test. For example, if a test calledvtr_ex_testinvtr_reg_nightly_test3was failing:#From the VTR root $ cd vtr_flow/tasks $ ../scripts/run_vtr_task.py regression_tests/vtr_reg_nightly_test3/vtr_ex_test
Next, generate new golden reference results using
parse_vtr_task.pyand the-create_goldenoption.$ ../scripts/python_libs/vtr/parse_vtr_task.py regression_tests/vtr_reg_nightly_test3/vtr_ex_test -create_golden
Lastly, check that the results match with the
-check_goldenoption$ ../scripts/python_libs/vtr/parse_vtr_task.py regression_tests/vtr_reg_nightly_test3/vtr_ex_test -check_golden
Once the -check_golden command passes, the changes to the golden result can be committed so that the reg test will pass in future runs of vtr_reg_nightly_test3.
Attention Even though the parsed files are located in different locations, the names of the parsed files should be different.
Adding Tests
Any time you add a feature to VTR you must add a test which exercises the feature. This ensures that regression tests will detect if the feature breaks in the future.
Consider which regression test suite your test should be added to (see Running Tests descriptions).
Typically, test which exercise new features should be added to vtr_reg_strong.
These tests should use small benchmarks to ensure they:
run quickly (so they get run often!), and
are easier to debug. If your test will take more than ~1 minute it should probably go in a longer running regression test (but see first if you can create a smaller testcase first).
Adding a test to vtr_reg_strong
This describes adding a test to vtr_reg_strong, but the process is similar for the other regression tests.
Create a configuration file
First move to the vtr_reg_strong directory:
#From the VTR root directory $ cd vtr_flow/tasks/regression_tests/vtr_reg_strong $ ls qor_geomean.txt strong_flyover_wires strong_pack_and_place strong_analysis_only strong_fpu_hard_block_arch strong_power strong_bounding_box strong_fracturable_luts strong_route_only strong_breadth_first strong_func_formal_flow strong_scale_delay_budgets strong_constant_outputs strong_func_formal_vpr strong_sweep_constant_outputs strong_custom_grid strong_global_routing strong_timing strong_custom_pin_locs strong_manual_annealing strong_titan strong_custom_switch_block strong_mcnc strong_valgrind strong_echo_files strong_minimax_budgets strong_verify_rr_graph strong_fc_abs strong_multiclock task_list.txt strong_fix_pins_pad_file strong_no_timing task_summary strong_fix_pins_random strong_pack
Each folder (prefixed with
strong_in this case) defines a task (sub-test).Let’s make a new task named
strong_mytest. An easy way is to copy an existing configuration file such asstrong_timing/config/config.txt$ mkdir -p strong_mytest/config $ cp strong_timing/config/config.txt strong_mytest/config/.
You can now edit
strong_mytest/config/config.txtto customize your test.Generate golden reference results
Now we need to test our new test and generate ‘golden’ reference results. These will be used to compare future runs of our test to detect any changes in behaviour (e.g. bugs).
From the VTR root, we move to the
vtr_flow/tasksdirectory, and then run our new test:#From the VTR root $ cd vtr_flow/tasks $ ../scripts/run_vtr_task.py regression_tests/vtr_reg_strong/strong_mytest regression_tests/vtr_reg_strong/strong_mytest ----------------------------------------- Current time: Jan-25 06:51 PM. Expected runtime of next benchmark: Unknown k6_frac_N10_mem32K_40nm/ch_intrinsics...OK
Next we can generate the golden reference results using
parse_vtr_task.pywith the-create_goldenoption:$ ../scripts/python_libs/vtr/parse_vtr_task.py regression_tests/vtr_reg_strong/strong_mytest -create_golden
And check that everything matches with
-check_golden:$ ../scripts/python_libs/vtr/parse_vtr_task.py regression_tests/vtr_reg_strong/strong_mytest -check_golden regression_tests/vtr_reg_strong/strong_mytest...[Pass]
Add it to the task list
We now need to add our new
strong_mytesttask to the task list, so it is run whenevervtr_reg_strongis run. We do this by adding the lineregression_tests/vtr_reg_strong/strong_mytestto the end ofvtr_reg_strong’stask_list.txt:#From the VTR root directory $ vim vtr_flow/tasks/regression_tests/vtr_reg_strong/task_list.txt # Add a new line 'regression_tests/vtr_reg_strong/strong_mytest' to the end of the file
Now, when we run
vtr_reg_strong:#From the VTR root directory $ ./run_reg_test.py vtr_reg_strong #Output trimmed... regression_tests/vtr_reg_strong/strong_mytest ----------------------------------------- #Output trimmed...
we see our test is run.
Commit the new test
Finally you need to commit your test:
#Add the config.txt and golden_results.txt for the test $ git add vtr_flow/tasks/regression_tests/vtr_reg_strong/strong_mytest/ #Add the change to the task_list.txt $ git add vtr_flow/tasks/regression_tests/vtr_reg_strong/task_list.txt #Commit the changes, when pushed the test will automatically be picked up by BuildBot $ git commit
Creating Unit Tests
You can find the source code for the unit tests in their respective directories. New unit tests must also be created in these directories.
Test |
Directory |
|---|---|
|
|
|
|
|
|
|
|
VTR uses Catch2 for its unit testing framework. For a full tutorial of how to use
the framework, see $VTR_ROOT/libs/EXTERNAL/libcatch2/docs/Readme.md.
Example: Creating and Running a VPR Test Case
Navigate to $VTR_ROOT/vpr/test.
$ cd $VTR_ROOT/vpr/test
From here, let’s create and open a new file test_new_vpr.cpp (begin the file name with test_). Be sure to #include "catch2/catch_test_macros.hpp".
Introduce a test case using the TEST_CASE macro, and include a name and a tag. For boolean assertions, use REQUIRE.
#include "catch2/catch_test_macros.hpp"
// To choose a tag (written with square brackets "[tag]"), see examples from when you run ./test_vpr
// --list-tests in the tester executable directory, as shown earlier. A good default tag name is the name
// of the tester: in this case, [vpr].
TEST_CASE("a_vpr_test_name", "[vpr]") {
int x = 0;
REQUIRE(x == 0);
}
To run our test case, we must navigate back to $VTR_ROOT/build/vpr (from the table
under Running Individual Testers). Since we created a test, we need to rebuild the
tester. Then, we can run our test.
$ cd $VTR_ROOT/build/vpr
$ make // rebuild tester
$ ./test_vpr a_vpr_test_name // run new unit test
Output:
Filters: "a_vpr_test_name"
Randomness seeded to: 2089861684
===============================================================================
All tests passed (1 assertion in 1 test case)
Debugging Aids
VTR has support for several additional tools/features to aid debugging.
Basic
To build a tool with make in debug mode, simply add BUILD_TYPE=debug at the end of your make command. For example, to build all tools in debug mode use:
$ make BUILD_TYPE=debug
You can also enable additional (verbose) output from some tools. To build vpr with both debug information and additional output, use:
$ make vpr BUILD_TYPE=debug VERBOSE=1
Sanitizers
VTR can be compiled using sanitizers which will detect invalid memory accesses, memory leaks and undefined behaviour (supported by both GCC and LLVM):
#From the VTR root directory
$ cmake -D VTR_ENABLE_SANITIZE=ON build
$ make
You can suppress reporting of known memory leaks in libraries used by vpr by setting the environment variable below:
LSAN_OPTIONS=suppressions=$VTR_ROOT/vpr/lsan.supp
where $VTR_ROOT is the root directory of your vtr source code tree.
Note that some of the continuous integration (CI) regtests (run automatically on pull requests) turn on sanitizers (currently S: Basic and R: Odin-II Basic Tests)
Valgrind
An alternative way to run vtr programs to check for invalid memory accesses and memory leaks is to use the valgrind tool. valgrind can be run on any build except the sanitized build, without recompilation. For example, to run on vpr use
#From the VTR root directory
valgrind --leak-check=full --suppressions=./vpr/valgrind.supp ./vpr/vpr [... usual vpr options here ...]
The suppression file included in the command above will suppress reporting of known memory leaks in libraries included by vpr.
Note that valgrind is run on some flows by the continuous integration (CI) tests.
Assertion Levels
VTR supports configurable assertion levels.
The default level (2) which turns on most assertions which don’t cause significant run-time penalties.
This level can be increased:
#From the VTR root directory
$ cmake -D VTR_ASSERT_LEVEL=3 build
$ make
this turns on more extensive assertion checking and re-builds VTR.
GDB Pretty Printers
To make it easier to debug some of VTR’s data structures with GDB.
STL Pretty Printers
It is helpful to enable STL pretty printers, which make it much easier to debug data structures using STL.
For example printing a std::vector<int> by default prints:
(gdb) p/r x_locs
$2 = {<std::_Vector_base<int, std::allocator<int> >> = {
_M_impl = {<std::allocator<int>> = {<__gnu_cxx::new_allocator<int>> = {<No data fields>}, <No data fields>}, _M_start = 0x555556f063b0,
_M_finish = 0x555556f063dc, _M_end_of_storage = 0x555556f064b0}}, <No data fields>}
which is not very helpful.
But with STL pretty printers it prints:
(gdb) p x_locs
$2 = std::vector of length 11, capacity 64 = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
which is much more helpful for debugging!
If STL pretty printers aren’t already enabled on your system, add the following to your .gdbinit file:
python
import sys
sys.path.insert(0, '$STL_PRINTER_ROOT')
from libstdcxx.v6.printers import register_libstdcxx_printers
register_libstdcxx_printers(None)
end
where $STL_PRINTER_ROOT should be replaced with the appropriate path to the STL pretty printers.
For example recent versions of GCC include these under /usr/share/gcc-*/python (e.g. /usr/share/gcc-9/python)
VTR Pretty Printers
VTR includes some pretty printers for some VPR/VTR specific types.
For example, without the pretty printers you would see the following when printing a VPR AtomBlockId:
(gdb) p blk_id
$1 = {
id_ = 71
}
But with the VTR pretty printers enabled you would see:
(gdb) p blk_id
$1 = AtomBlockId(71)
To enable the VTR pretty printers in GDB add the following to your .gdbinit file:
python
import sys
sys.path.insert(0, "$VTR_ROOT/dev")
import vtr_gdb_pretty_printers
gdb.pretty_printers.append(vtr_gdb_pretty_printers.vtr_type_lookup)
end
where $VTR_ROOT should be replaced with the root of the VTR source tree on your system.
RR (Record Replay) Debugger
RR extends GDB with the ability to record a run of a tool and then re-run it to reproduce any observed issues. RR also enables efficient reverse execution (!) which can be extremely helpful when tracking down the source of a bug.
Speeding up the edit-compile-test cycle
Rapid iteration through the edit-compile-test/debug cycle is very helpful when making code changes to VTR.
The following is some guidance on techniques to reduce the time required.
Speeding Compilation
Parallel compilation
For instance when building VTR using make, you can specify the
-j Noption to compile the code base with N parallel jobs:$ make -j N
A reasonable value for
Nis equal to the number of threads you system can run. For instance, if your system has 4 cores with HyperThreading (i.e. 2-way SMT) you could run:$ make -j8
Building only a subset of VTR
If you know your changes only effect a specific tool in VTR, you can request that only that tool is rebuilt. For instance, if you only wanted to re-compile VPR you could run:
$ make vpr
which would avoid re-building other tools (e.g. ODIN, ABC).
Use ccache
ccache is a program which caches previous compilation results. This can save significant time, for instance, when switching back and forth between release and debug builds.
VTR’s cmake configuration should automatically detect and make use of ccache once it is installed.
For instance on Ubuntu/Debian systems you can install ccache with:
$ sudo apt install ccache
This only needs to be done once on your development system.
Disable Interprocedural Optimizatiaons (IPO)
IPO re-optimizes an entire executable at link time, and is automatically enabled by VTR if a supporting compiler is found. This can notably improve performance (e.g. ~10-20% faster), but can significantly increase compilation time (e.g. >2x in some cases). When frequently re-compiling and debugging the extra execution speed may not be worth the longer compilation times. In such cases you can manually disable IPO by setting the cmake parameter
VTR_IPO_BUILD=off.For instance using the wrapper Makefile:
$ make CMAKE_PARAMS="-DVTR_IPO_BUILD=off"
Note that this option is sticky, so subsequent calls to make don’t need to keep specifying VTR_IPO_BUILD, until you want to re-enable it.
This setting can also be changed with the ccmake tool (i.e.
ccmake build).
All of these option can be used in combination. For example, the following will re-build only VPR using 8 parallel jobs with IPO disabled:
make CMAKE_PARAMS="-DVTR_IPO_BUILD=off" -j8 vpr
Profiling VTR
Use GNU Profiler gprof
Installation: Install
gprof,gprof2dot, andxdot(optional).gprofis part of GNU Binutils, which is a commonly-installed package alongside the standard GCC package on most systems.gprofshould already exist. If not, usesudo apt install binutils.gprof2dotrequires python3 or conda. You can install withpip3 install gprof2dotorconda install -c conda-forge gprof2dot.xdotis optional. To install it, usesudo apt install.
sudo apt install binutils pip3 install gprof2dot sudo apt install xdot # optional
Contact your administrator if you do not have the
sudorights.VPR build: Use the CMake option below to enable VPR profiler build.
make CMAKE_PARAMS="-DVTR_ENABLE_PROFILING=ON" vpr
Profiling:
With the profiler build, each time you run the VTR flow script, it will produce an extra file
gmon.outthat contains the raw profile information. Rungprofto parse this file. You will need to specify the path to the VPR executable.gprof $VTR_ROOT/vpr/vpr gmon.out > gprof.txt
Next, use
gprof2dotto transform the parsed results to a.dotfile (Graphviz graph description), which describes the graph of your final profile results. If you encounter long function names, specify the-soption for a cleaner graph. For other useful options, please refer to its online documentation.gprof2dot -s gprof.txt > vpr.dot
Note: You can chain the above commands to directly produce the
.dotfile:gprof $VTR_ROOT/vpr/vpr gmon.out | gprof2dot -s > vpr.dot
Visualization:
Option 1 (Recommended): Use the Edotor online Graphviz visualizer.
Open a browser and go to https://edotor.net/ (on any device, not necessarily the one where VPR is running).
Choose
dotas the “Engine” at the top navigation bar.Next, copy and paste
vpr.dotinto the editor space on the left side of the web view.Then, you can interactively (i.e., pan and zoom) view the results and download an SVG or PNG image.
Option 2: Use the locally-installed
xdotvisualization tool.Use
xdotto view your results:xdot vpr.dot
To save your results as a PNG file:
dot -Tpng -Gdpi=300 vpr.dot > vpr.png
Note that you can use the
-Gdpioption to make your picture clearer if you find the default dpi settings not clear enough.
Use Linux Perf Tool
Installation: Install
perfandgprof2dot(optional).sudo apt install linux-tools-common linux-tools-generic pip3 install gprof2dot # optional
VPR build: No need to enable any CMake options for using
perf, unless you want to utilize specific features, such asperf annotate.make vpr
Profiling:
perfneeds to know the process ID (i.e., pid) of the running VPR you want to monitor and profile, which can be obtained using the Linux commandtop -u <username>.Option 1: Real-time analysis
sudo perf top -p <vpr pid>
Option 2 (Recommended): Record and offline analysis
Use
perf recordto record the profile data and the call graph. (Note: The argumentlbrfor--call-graphonly works on Intel platforms. If you encounter issues with call graph recording, please refer to theperf recordmanual for more information.)sudo perf record --call-graph lbr -p <vpr pid>
After VPR completes its run, or if you stop
perfwith CTRL+C (if you are focusing on a specific portion of the VPR execution), theperftool will produce an extra fileperf.datacontaining the raw profile results in the directory where you ranperf. You can further analyze the results by parsing this file usingperf report.sudo perf report -i perf.data
Note 1: The official
perfwiki and tutorial are highly recommended for those who want to explore more uses of the tool.Note 2: It is highly recommended to run
perfwithsudo, but you can find a workaround here to allow runningperfwithout root rights.Note 3: You may also find Hotspot useful if you want to run
perfwith GUI support.
Visualization (optional): If you want a better illustration of the profiling results, first run the following command to transform the
perfreport into a Graphviz dot graph. The remaining steps are exactly the same as those described under Use GNU Profiler gprof .perf script -i perf.data | c++filt | gprof2dot.py -f perf -s > vpr.dot
External Subtrees
VTR includes some code which is developed in external repositories, and is integrated into the VTR source tree using git subtrees.
To simplify the process of working with subtrees we use the dev/external_subtrees.py script.
For instance, running ./dev/external_subtrees.py --list from the VTR root it shows the subtrees:
Component: abc Path: abc URL: https://github.com/berkeley-abc/abc.git URL_Ref: master
Component: libargparse Path: libs/EXTERNAL/libargparse URL: https://github.com/kmurray/libargparse.git URL_Ref: master
Component: libblifparse Path: libs/EXTERNAL/libblifparse URL: https://github.com/kmurray/libblifparse.git URL_Ref: master
Component: libsdcparse Path: libs/EXTERNAL/libsdcparse URL: https://github.com/kmurray/libsdcparse.git URL_Ref: master
Component: libtatum Path: libs/EXTERNAL/libtatum URL: https://github.com/kmurray/tatum.git URL_Ref: master
Code included in VTR by subtrees should not be modified within the VTR source tree. Instead changes should be made in the relevant up-stream repository, and then synced into the VTR tree.
Updating an existing Subtree
The following are instructions on how to pull in external changes from an existing subtree. Which instructions to follow depend on if you are changing the external ref or not.
External Ref Does Not Change
These instructions are for if the subtree is tracking a ref of a repo which has changes we want to pull in. For example, if the subtree is tracking main/master.
From the VTR root run:
./dev/external_subtrees.py $SUBTREE_NAME, where$SUBTREE_NAMEis the name of an existing subtree.For example to update the
libtatumsubtree:./dev/external_subtrees.py --update libtatum -m "commit message describing why component is being updated"
External Ref Changes
These instructions are for if you want to change the ref that a subtree is tracking. For example, if you want to change the version of a subtree (which exists on a different branch).
Update
./dev/subtree_config.xmlwith the new external ref.Run
git log <internal_path>and take note of any local changes to the subtree. It is bad practice to have local changes to subtrees you cannot modify; however, some changes must be made to allow the library to work in VTR. The next step will clear all these changes, and they may be important and need to be recreated.Delete the subtree folder (the internal path) entirely and commit it to git. The issue is that changing the external ref basically creates a new subtree, so the regular way of updating the subtree does not work. You need to completely wipe all of the code from the old subtree. NOTE: This will remove all changes locally made to the subtree.
Run
./dev/external_subtrees.py --update $SUBTREE_NAME. This will pull in the most recent version of the subtree, squash the changes, and raise a commit.Recreate the local changes from step 2 above, such that the library builds without issue; preferably in a concise way such that the library can be easily updated in the future.
Adding a new Subtree
To add a new external subtree to VTR do the following:
Add the subtree specification to
dev/subtree_config.xml.For example to add a subtree name
libfoofrom themasterbranch ofhttps://github.com/kmurray/libfoo.gittolibs/EXTERNAL/libfooyou would add:<subtree name="libfoo" internal_path="libs/EXTERNAL/libfoo" external_url="https://github.com/kmurray/libfoo.git" default_external_ref="master"/>
within the existing
<subtrees>tag.Note that the internal_path directory should not already exist.
You can confirm it works by running:
dev/external_subtrees.py --list:Component: abc Path: abc URL: https://github.com/berkeley-abc/abc.git URL_Ref: master Component: libargparse Path: libs/EXTERNAL/libargparse URL: https://github.com/kmurray/libargparse.git URL_Ref: master Component: libblifparse Path: libs/EXTERNAL/libblifparse URL: https://github.com/kmurray/libblifparse.git URL_Ref: master Component: libsdcparse Path: libs/EXTERNAL/libsdcparse URL: https://github.com/kmurray/libsdcparse.git URL_Ref: master Component: libtatum Path: libs/EXTERNAL/libtatum URL: https://github.com/kmurray/tatum.git URL_Ref: master Component: libfoo Path: libs/EXTERNAL/libfoo URL: https://github.com/kmurray/libfoo.git URL_Ref: master
which shows libfoo is now recognized.
Run
./dev/external_subtrees.py --update $SUBTREE_NAMEto add the subtree.For the
libfooexample above this would be:./dev/external_subtrees.py --update libfoo
This will create two commits to the repository. The first will squash all the upstream changes, the second will merge those changes into the current branch.
Pushing VTR Changes Back to Upstream Subtree
If there are changes in the VTR repo in a subtree that should be merged back into the source repo of the subtree, the changes can be pushed back manually.
The instructions above used a Python script to simplify updating subtrees in VTR. This is fine for pulling in changes from a remote repo; however, it is not good for pushing changes back. This is because these changes need to be pushed somewhere, and it is not a good idea to just push it back to the master branch directly. Instead, it should be pushed to a temporary branch. Then a PR can be made to bring the changes into the target repo.
To push changes VTR made to a subtree do the following:
Create a fork of the target repo. Optionally you can create a branch to be the target of the push, or you can just use master.
Run:
cd $VTR_ROOT git subtree push --prefix=<subtree_path> <forked_repo_url> <branch_name>
The prefix is the internal path to the subtree, as written in
dev/subtree_config.xml.Create a PR from your forked repo to the main repo, sharing the amazing changes with the world.
Tutorial: Syncing Tatum with VTR
This tutorial will show you how to synchronize libtatum in VTR and
Tatum; however, similar steps
can be done to synchronize any subtree in VTR.
First, we will pull in (update) any changes in Tatum that are not in VTR yet. On a clean branch (based off master), execute the following:
cd $VTR_ROOT
./dev/external_subtrees.py --update libtatum -m "Pulling in changes from Tatum."
If the output in the terminal says Subtree is already at commit <commit_hash>,
then there is nothing to pull in. If it says changes were pulled in, a commit
would have already been made for you. Push these changes to your branch and
raise a PR on VTR to merge these changes in.
After pulling in all the changes from Tatum, without changing branches, we will push our VTR changes to Tatum. This is a bit more complicated since, as stated in the section on pushing to subtrees, the changes cannot just be pushed to master.
Create a fork of Tatum and make sure the master branch of that fork is synchronized with Tatum’s master branch. Then execute the following:
cd $VTR_ROOT
git subtree push --prefix=libs/EXTERNAL/libtatum <forked_repo_url> master
After that command finishes, raise a PR from your forked repo onto the Tatum repo for the changes to be reviewed and merged in.
Subtree Rationale
VTR uses subtrees to allow easy tracking of upstream dependencies.
Their main advantages included:
Works out-of-the-box: no actions needed post checkout to pull in dependencies (e.g. no
git submodule update --init --recursive)Simplified upstream version tracking
Potential for local changes (although in VTR we do not use this to make keeping in sync easier)
See here for a more detailed discussion.
Finding Bugs with Coverity
Coverity Scan is a static code analysis service which can be used to detect bugs.
Browsing Defects
To view defects detected do the following:
Get a coverity scan account
Contact a project maintainer for an invitation.
Browse the existing defects through the coverity web interface
Submitting a build
To submit a build to coverity do the following:
Download the coverity build tool
Configure VTR to perform a debug build. This ensures that all assertions are enabled, without assertions coverity may report bugs that are guarded against by assertions. We also set VTR asserts to the highest level.
#From the VTR root mkdir -p build cd build CC=gcc CXX=g++ cmake -DCMAKE_BUILD_TYPE=debug -DVTR_ASSERT_LEVEL=3 ..
Note that we explicitly asked for gcc and g++, the coverity build tool defaults to these compilers, and may not like the default ‘cc’ or ‘c++’ (even if they are linked to gcc/g++).
Run the coverity build tool
#From the build directory where we ran cmake cov-build --dir cov-int make -j8
Archive the output directory
tar -czvf vtr_coverity.tar.gz cov-int
Submit the archive through the coverity web interface
Once the build has been analyzed you can browse the latest results through the coverity web interface
No files emitted
If you get the following warning from cov-build:
[WARNING] No files were emitted.
You may need to configure coverity to ‘know’ about your compiler. For example:
```shell
cov-configure --compiler `which gcc-7`
```
On unix-like systems run scan-build make from the root VTR directory.
to output the html analysis to a specific folder, run scan-build make -o /some/folder
Release Procedures
General Principles
We periodically make ‘official’ VTR releases. While we aim to keep the VTR master branch stable through-out development some users prefer to work off of an official release of VTR. Historically this has coincided with the publishing of a paper detailing and carefully evaluating the changes from the previous VTR release. This is particularly helpful for giving academics a named, baseline version of VTR to which they can compare which has a known quality.
In preparation for a release it may make sense to produce ‘release candidates’ which, when fully tested and evaluated (and after any bug fixes), become the official release.
Checklist
The following outlines the procedure to following when making an official VTR release:
Check that the code compiles on the list of supported compilers
Check that all regression tests pass functionality
Update regression test golden results to match the released version
Check that all regression tests pass QoR
Create a new entry in the CHANGELOG.md for the release, summarizing at a high-level user-facing changes
Increment the version number (set in the root CMakeLists.txt)
Create a git annotated tag (e.g.
v8.0.0) and push it to github. Note: tagged releases should always be off of Master, and not off of any other branch. Tagging releases off of other branches can be dangerous since that branch may be deleted in the future and git tools (such as git describe) may rely on tags being on the main development branch (which is master in our case).GitHub will automatically create a release based on the tag
Add the new change log entry to the GitHub release description
Update the ReadTheDocs configuration to build and serve documentation for the relevant tag (e.g.
v8.0.0)Send a release announcement email to the vtr-announce mailing list (make sure to thank all contributors!)